Как включить распознавание речи¶
Записи звука с компьютеров сотрудников могут быть преобразованы в текст с помощью:
Сервера распознавания Staffcop.
Внимание
Используйте отдельный сервер для установки службы распознавания.
Облачного модуля T-Bank VoiceKit.
Внимание
Для работы облачного модуля обеспечьте для сервера Staffcop доступ к адресам voicekit.tinkoff.ru и api.tinkoff.ai.Адреса находятся на территории РФ.
См.также
Сервер распознавания Staffcop¶
Сервер распознавания устанавливается на отдельную от сервера Staffcop Enterprise машину.
Он поддерживает не только преобразование речи в текст, но и распознавание графических объектов.
Облачный модуль T-Bank VoiceKit¶
VoiceKit разработан компанией T-Bank. Он не использует зарубежные технологии и не передает данные за пределы собственного дата-центра, на котором происходит обработка аудио.
Модуль поддерживает многопоточную работу и может одновременно обрабатывать несколько аудиофайлов.
Оплата модуля принимается через личный кабинет на сайте T-Bank Software.
Примечание
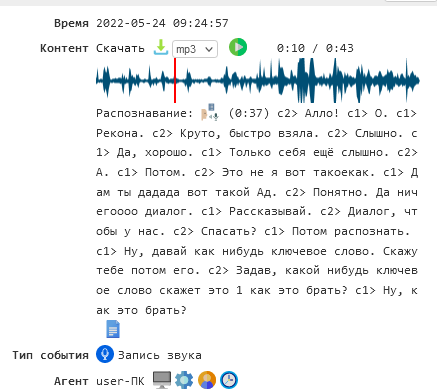
Пример распознанного диалога, где с1 и с2 — первый и второй собеседники:
Настройка и активация модуля¶
Чтобы включить модуль распознавания:
Перейдите в личный кабинет на сайте software.tbank.ru.
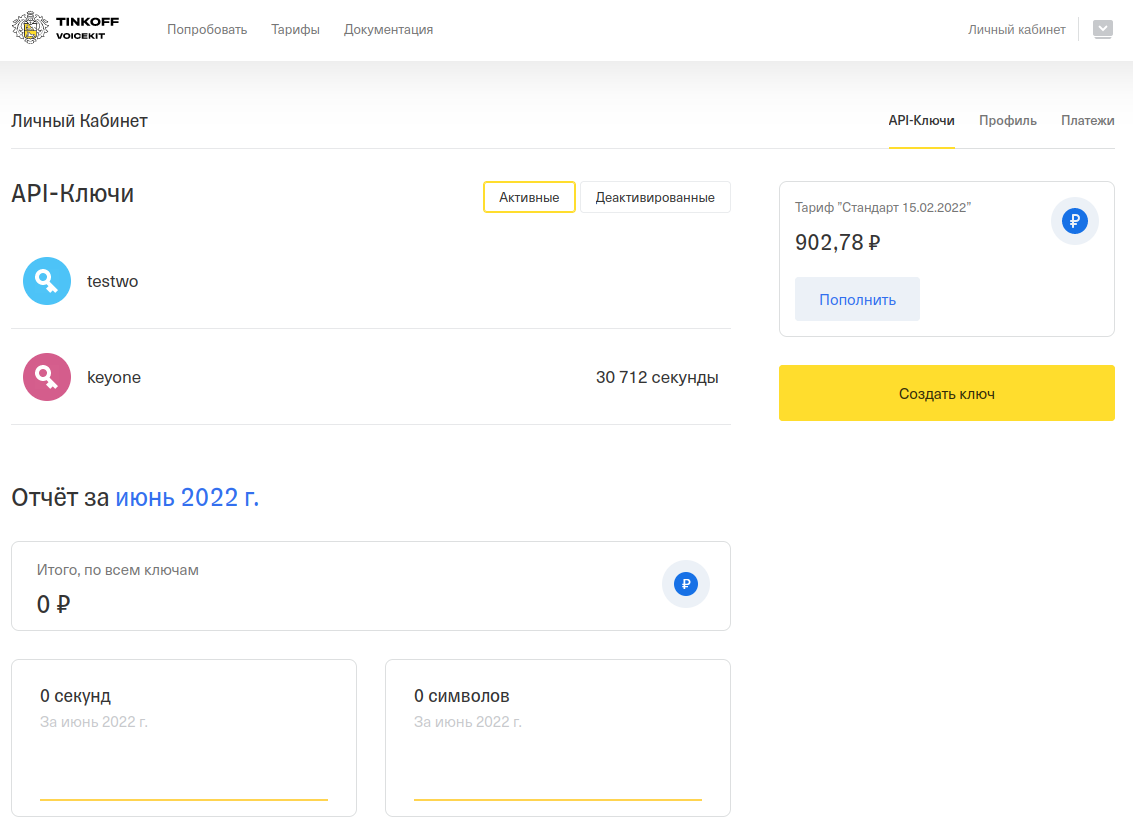
Нажмите на Создать ключ и введите название и описание ключа.
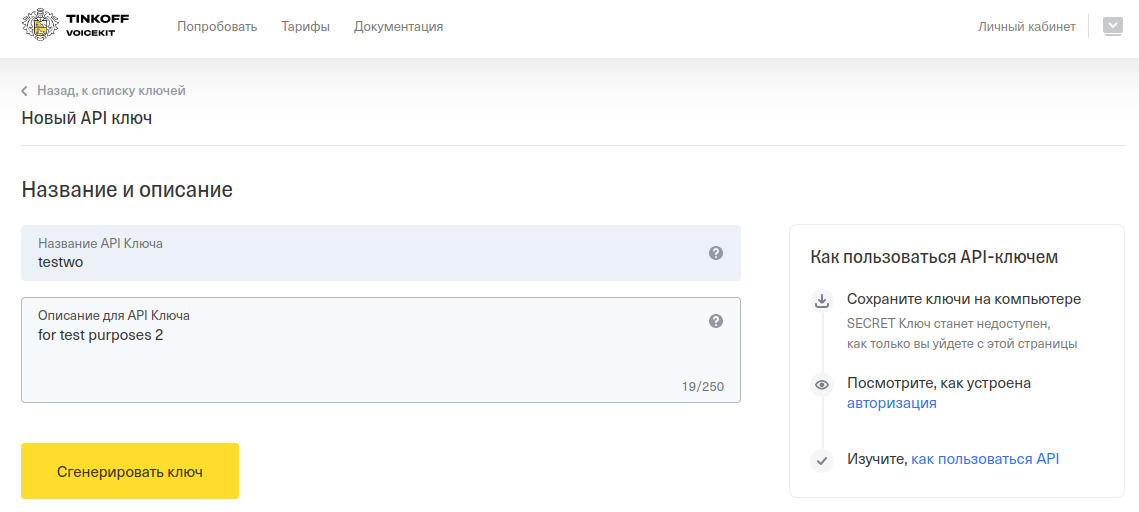
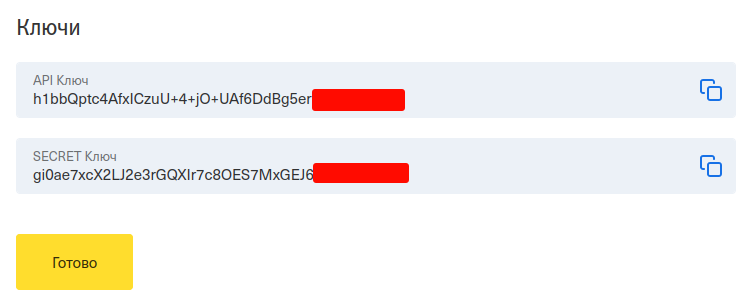
Нажмите Сгенерировать ключ и скопируйте полученные API Key и Secret Key.
Предупреждение
Сохраните ключи на компьютере. Secret Key станет недоступен, как только вы уйдете со страницы создания ключа.
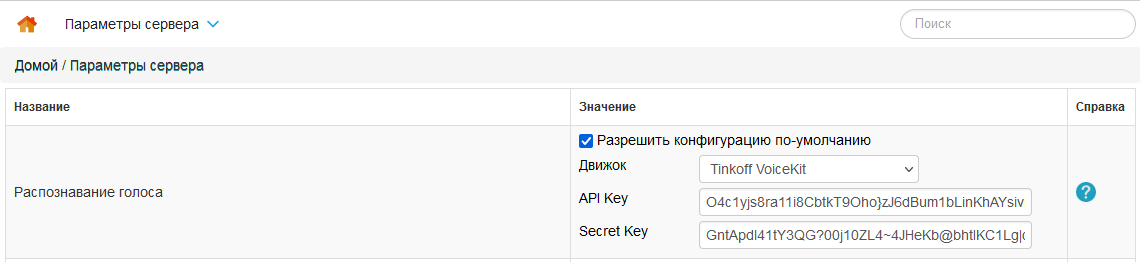
В Staffcop перейдите в раздел Панель управления → Параметры сервера.
В строке Распознавание голоса настройте параметры:
Разрешить конфигурацию по-умолчанию — активирует распознавание в стандартной конфигурации агентов;
Движок → Tinkoff VoiceKit — выберите движок для распознавания речи;
API Key и Secret Key — введите значения, полученные при генерации ключа в T-Bank VoiceKit;
опционально: Принудительно — чтобы начать распознавание всех записей с самой первой.
Нажмите кнопку Сохранить. Теперь распознавание речи включено и готово к работе.
Распознавание аудиозаписей¶
Для распознавания речи в текст доступны два инструмента:
распознавание одной записи,
политика распознавания речи.
Единоразовое распознавание¶
Не требует отдельной политики. Предназначено для демонстрации технологии и проверки работы.
Нажмите на кнопку Распознавание под событием Запись звука в Линзе событий. Система переведет речь в текст.

Политика Распознавание речи¶
Для фонового распознавания речи из поступающих событий настройте политику Распознавание речи.
Политика позволяет:
непрерывно распознавать текст,
накапливать текстовую базу данных,
анализировать данные с помощью встроенных политик распознавания, включая словари, регулярные выражения и политики безопасности.
Чтобы включить политику распознавания:
Перейдите во вкладке Политики в папку Политики → Анализ контента и откройте Распознавание речи.
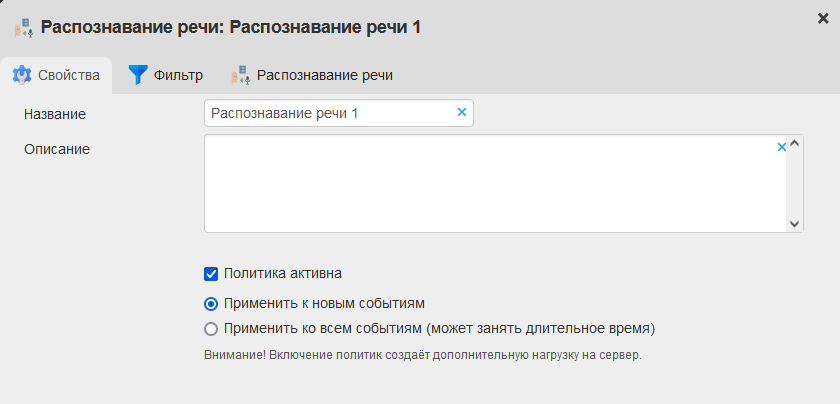
В окне политики включите флаг Политика активна.
Перейдите во вкладку Фильтр и при необходимости добавьте ограничения.
Примечание
Укажите конкретные компьютеры или пользователей, чтобы ускорить процесс распознавания.
Перейдите на вкладку Распознавание речи и выберите Движок → Tinkoff VoiceKit,
Заполните поля API Key и Secret Key.
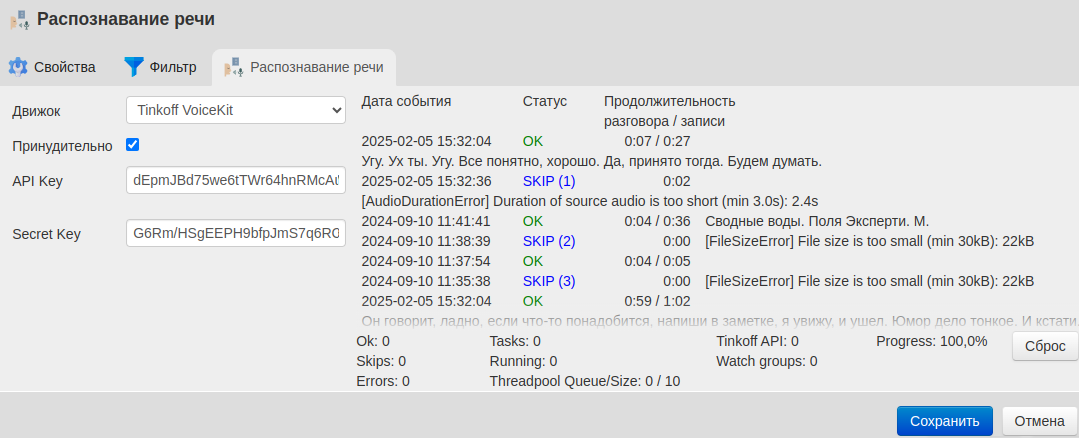
Сохраните изменения.
Дополнительно¶
Ограничения по размеру файла¶
Перед распознаванием речи происходит предварительная проверка размера файла:
минимальный размер — 30 КБ, соответствует примерно 1–2 секундам записи;
максимальный размер — 30 МБ, 10 минут записи весят около 5 МБ.
Если запись больше 20 минут, могут возникнуть проблемы с отрисовкой аудиодорожки.
Чтобы убрать отрисовку для больших аудиозаписей, укажите Максимальный размер аудиофайла (Mb) для визуализатора в Локальных настройках.
Настройка через командную строку¶
Дополнительные параметры модуля распознавания можно задать в файле локальной конфигурации сервера /etc/staffcop/config.
Откройте файл config:
sudo nano /etc/staffcop/config
Добавьте в конец файла ключи T-Bank VoiceKit:
TINKOFF_API_KEY = '...' TINKOFF_SECRET_KEY = '...'
При необходимости добавьте дополнительные опции и сохраните изменения:
включить отладочную информацию:
SPEECH_RECOGNITION_DEBUGминимальная продолжительность аудиозаписи, по умолчанию 3 секунды:
SPEECH_RECOGNITION_AUDIO_DURATION_MIN = 3время устаревания JWT-токена, который используется в API Tinkoff, по умолчанию 600 секунд:
TINKOFF_JWT_EXPIRATION = 600максимальное количество попыток распознавания, по умолчанию 5:
SPEECH_RECOGNITION_ATTEMPTS_LIMIT = 5
Перезапустите сервер:
staffcop restart
После перезапуска будут применены новые настройки распознавания речи.
Последнее обновление: 05.06.26