Политики распознавания контента¶
Позволяют отправлять события на сервер распознавания контента. Находятся на вкладке Политики в папке Политика → Анализ контента.
Чтобы включить распознавание контента:
В разделе Политики перейдите во вкладку Политики → Анализ контента.
Включите политики для контента, который вы хотите распознать.
В Анализе контента есть политики, которые не требуют сервера распознавания:
Извлечение текста — сохраняет текст из события Перехваченный файл.
Сканер архивов — сохраняет файлы из архива в событии Перехваченный файл.
Распознавание текста¶
Автоматически распознает текст на изображениях.
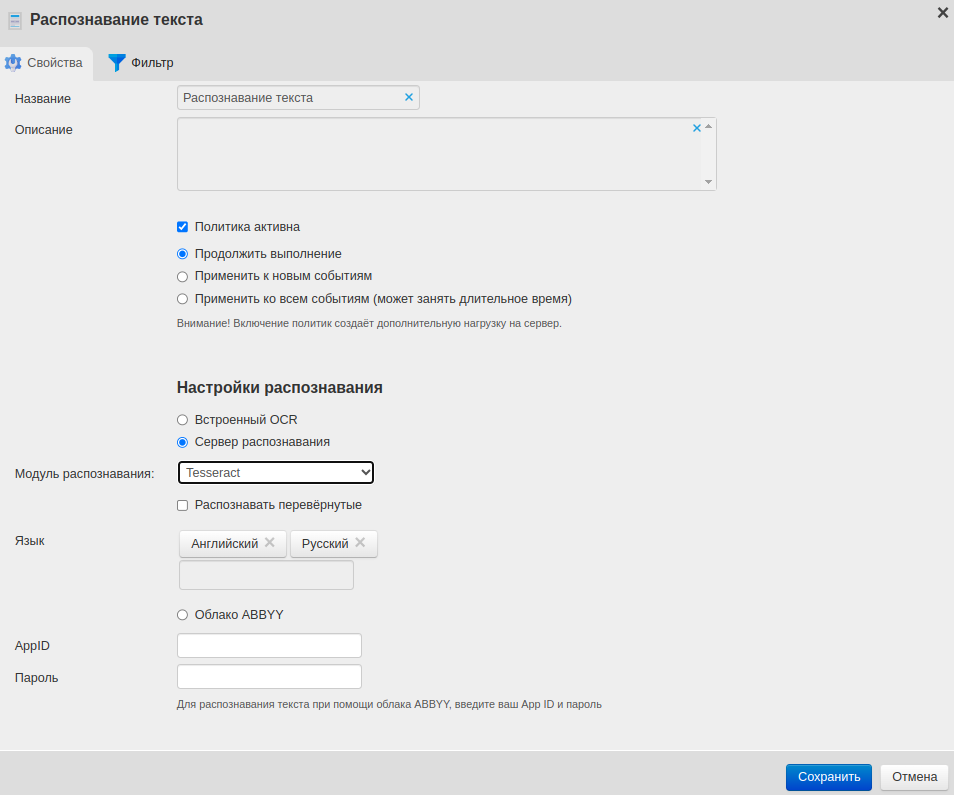
Формат изображения |
Время на обработку, с |
full HD изображение без поворота |
5 |
4K изображение |
20 |
Изображение печати, паспорта, картинки в формате JPEG |
4—6 |
Распознавание лица |
5—60 |
Чтобы включить распознавание текста:
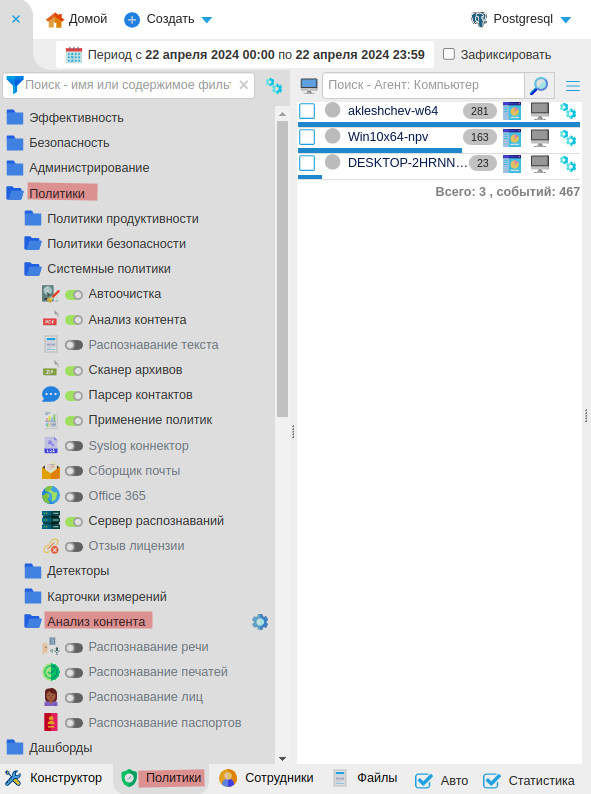
В папке Политики → Анализ контента откройте политику Распознавание текста.
В Окне свойств политики включите флаг Политика активна.
Выберите инструмент распознавания:
Встроенный OCR — OCR для распознавания изображений, встроенный в сервер Staffcop.
См.также
Сервер распознавания — отдельный сервер распознавания.
Укажите движок в поле Модуль распознавания.
Tesseract — бесплатная библиотека для базового распознавания контента.
Content AI ABBYY — платный движок. Для работы требуется дополнительная настройка сервера и платная лицензия с компонентом OCR.
Обеспечивает высокую точность распознавания перевернутых изображений.
Включите опцию Распознавать перевернутые, если хотите распознавать текст на перевернутых изображениях. Повышает нагрузку на сервер распознавания.
Выберите Язык для распознавания текста.
В разделе Облако ABBYY можно подключить аккаунт облака ABBYY, если он у вас есть.
включите флаг Облако ABBYY,
введите логин в поле AppID и Пароль.
Добавьте условия во вкладке Фильтр при необходимости.
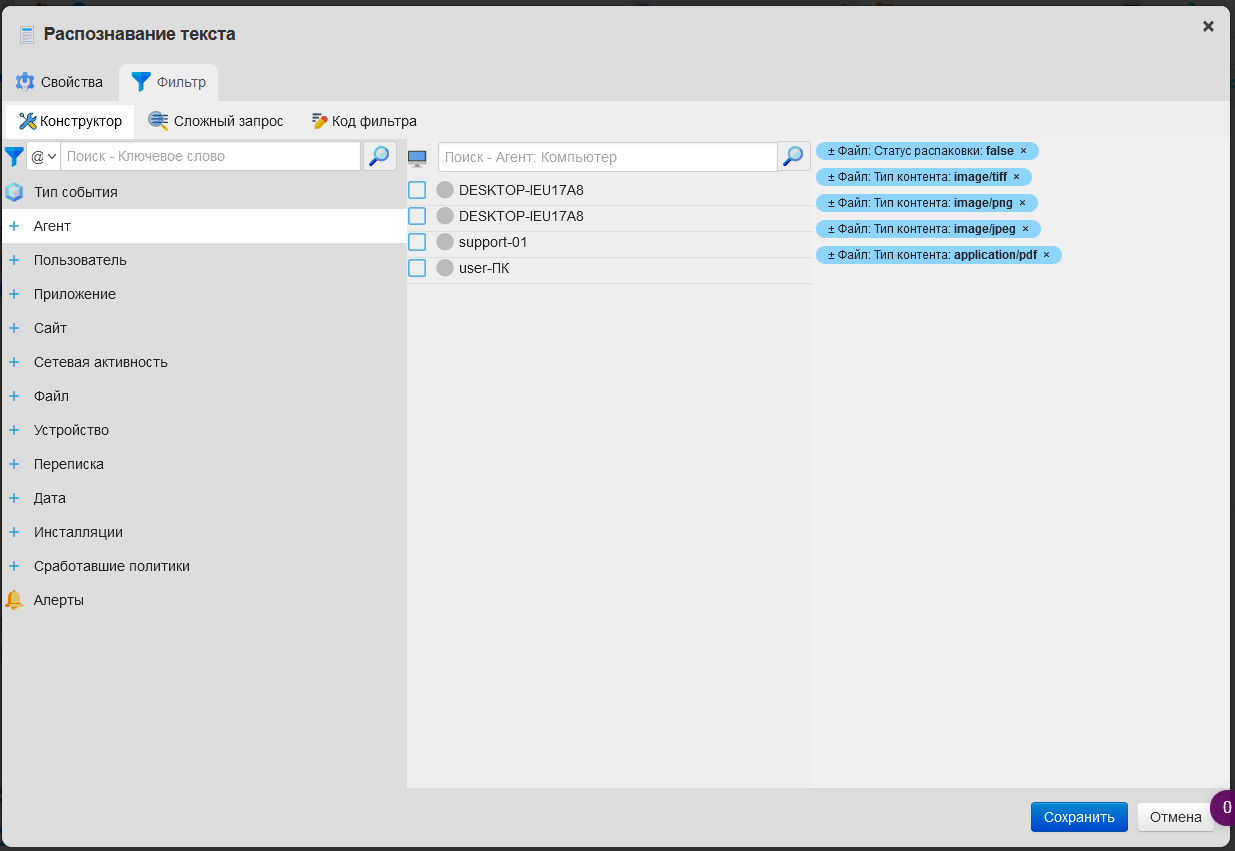
По умолчанию обрабатываются файлы в формате pdf, jpg, png и tiff из событий Перехваченный файл.
agent_attachedfile@mime:mime=application/pdf
agent_attachedfile@mime:mime=image/jpeg
agent_attachedfile@mime:mime=image/png
agent_attachedfile@mime:mime=image/tiff
agent_attachedfile@extracted:extracted=false
agent_eventtype@default:agent_eventtype=0#Intercepted file
{
"operator": "AND",
"rules": []
}
Распознавание речи¶
Переводит аудиозаписи речи из событий Запись звука в текст. Распознавание доступно для файлов с расширениями .mp3, .mpeg и .asf.
Для распознавания речи можно использовать:
Сервер распознавания,
Внимание
Распознавание речи на сервере распознавания доступно только с версии Staffcop 5.6.5.
Обновите сервер, если вы установили сервер распознавания на более ранней версии. Для обновления обратитесь в службу технической поддержки.
Чтобы включить распознавание речи:
В папке Политики → Анализ контента откройте Распознавание речи.
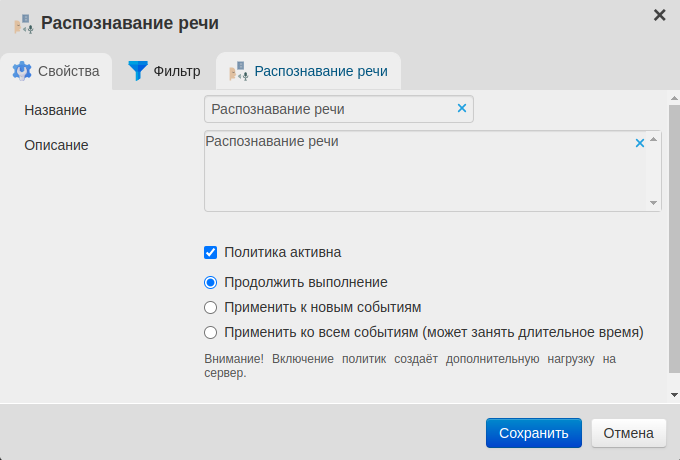
В окне политики включите флаг Политика активна.
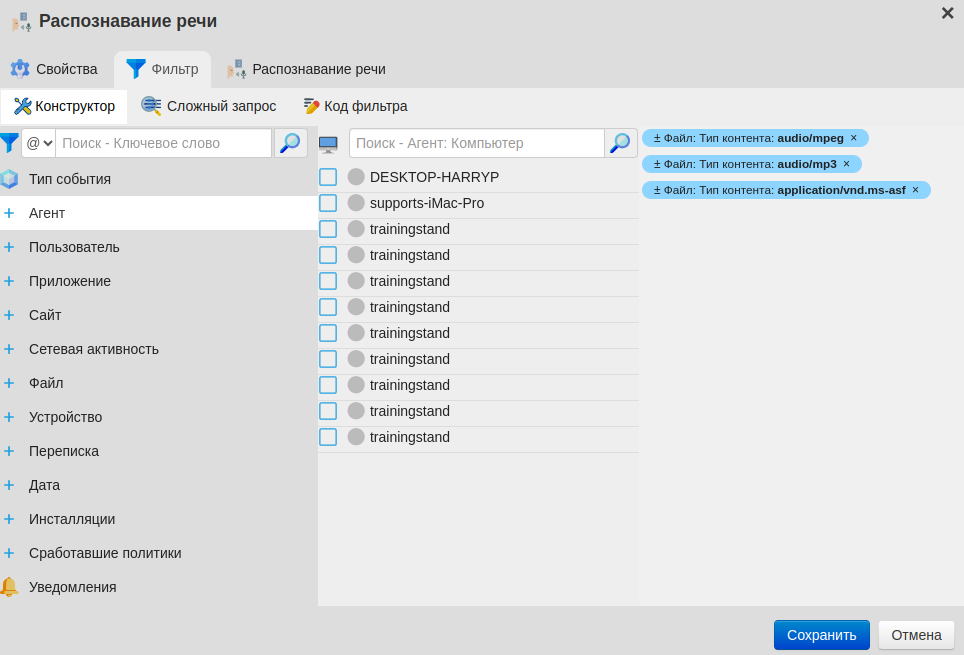
Перейдите во вкладку Фильтр и при необходимости добавьте условия.
Важно
События Запись звука приходят на сервер Staffcop с расширением .asf. Убедитесь, что в фильтре добавлено значение + Файл: Тип контента → application/vnd.ms-asf.
Примечание
Укажите конкретные компьютеры или пользователей, чтобы ускорить процесс распознавания.
Перейдите на вкладку Распознавание речи и выберите Движок → Сервер распознавания,
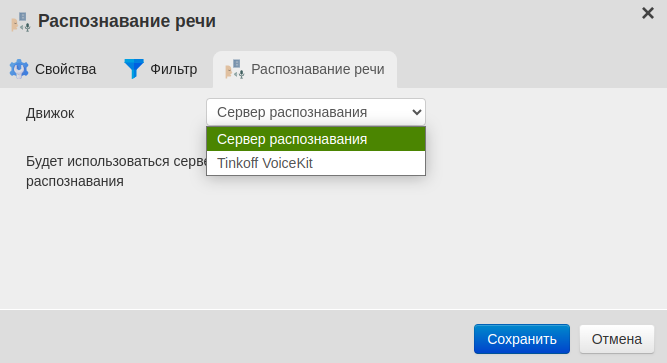
Сохраните изменения.
После этого поступающие события Запись звука будут отправлены на сервер распознавания для транскрибации.
Точность распознавания речи¶
По умолчанию для распознавания речи включена быстрая модель, однако результаты распознавания могут быть небезупречны.
При необходимости можно использовать более точную модель, однако скорость распознавания снизится. Чтобы включить ее:
Подключитесь к серверу распознавания по SSH.
Откройте конфигурационный файл сервера распознавания в текстовом редакторе:
sudo nano /etc/staffcop/cpservice-config
Добавьте в него значение:
WHISPER_MODEL = 'whisper.cpp/models/ggml-model-whisper-medium-q5_0.bin'
Сохраните изменения.
Перезапустите службу распознавания командой:
service staffcop-cpservice restart
Распознавание печатей¶
Сервер распознаваний находит изображения печати по заданным образцам в документах формата jpg, jpe, jpeg, png и pdf.
Примечание
Поддерживается поиск только круглых печатей.
Для работы политики понадобятся образцы печатей — фрагменты изображений, на котором содержится печать. Окружающий текст и подписи не являются помехами для распознавания.
Требования к образцам печати:
размер изображения — 400x400px;
разная степень нажатия при печати;
небольшие различия между образцами;
отсутствие бракованных оттисков;
расположение печатей под разными углами.
Подсказка
Используйте несколько образцов печати, чтобы улучшить качество распознавания.
Чтобы настроить распознавание печатей:
В папке Политики → Анализ контента откройте настройки политики Распознавание печатей.
В окне свойств политики включите флаг Политика активна.
В разделе Выбор изображений с печатями через кнопку Выбрать файл загрузите образец печати.
Дождитесь, когда у распознанных печатей в столбце Статус появится галочка.
Задайте фильтр для политики. Например:
Типы контента — pdf, jpg, png;
Типы события — перехваченные файлы или скриншоты.
Примечание
Политика не работает без условий. Не пропускайте этот шаг.
Нажмите кнопку Сохранить.
Результаты будут доступны в разделе Сработавшие политики.
Добавить дополнительные образцы печати:
Нажмите кнопку + Создать → Распознавание печатей. Откроется окно создания политики.
Включите опцию Политика активна.
Нажмите кнопку Сохранить.
Откройте на вкладке Политики новую политику Распознавание печатей.
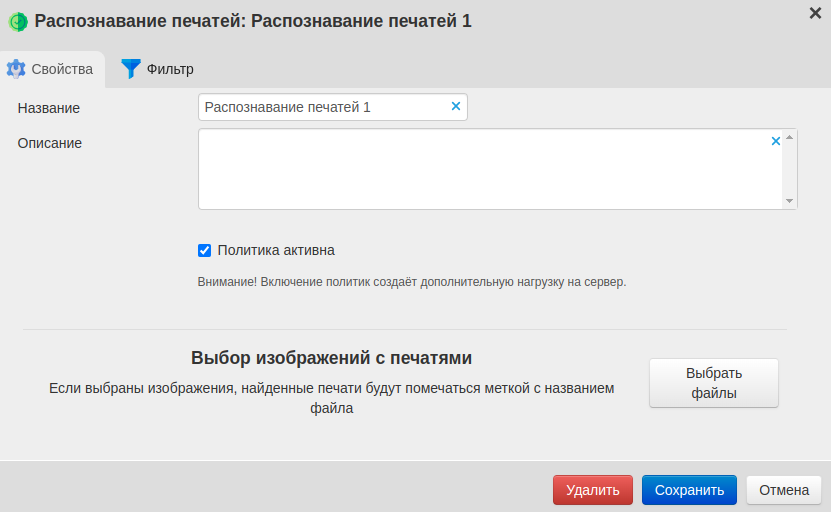
5. В разделе Выбор изображений с печатями через кнопку Выбрать файл загрузите образецы печати. 4. Дождитесь, когда у распознанных печатей в столбце Статус появится галочка. 5. Задайте фильтр для политики. 6. Нажмите кнопку Сохранить.
Точность распознавания печатей¶
Если есть несколько схожих образцов печатей, могут происходить ложные срабатывания.
Ложные срабатывания возможны, когда компания или организация имеют похожие печати с разными названиемм отдела или кодами подразделений. В этом случае обратитесь в техническую поддержку.
Чтобы снизить количество ложных срабатываний:
Откройте конфигурационный файл сервера Staffcop:
sudo nano /usr/share/staffcop/settings.py
Уменьшите значение параметра STAMP_RECOGNITION_THRESHOLD.
Сохраните файл и перезапустите Staffcop:
sudo service staffcop restart
Распознавание лиц¶
Сервер распознавания может распознавать лица на снимках веб-камер.
Результат распознавания фиксируется в уведомлениях:
Нет лица — лица не обнаружены;
Cвое лицо — обнаружено лицо владельца ПК;
Неизвестное лицо — обнаружено неизвестное лицо, которого нет в базе;
Несколько лиц — на снимке присутствует несколько лиц;
Нет снимка — снимок нечитаемый: темнота, помехи, отсутствие резкости и т. п.
Cвое лицо и Неизвестное лицо определяются по снимкам, которые были заранее загружены в систему.
Чтобы включить распознавание лиц:
В /usr/share/staffcop/settings.py добавьте запись:
FACES_TYPES = ( "WebcamSnapshot")См.также
Также доступно распознавание иных изображений, кроме снимков веб-камер.
Сохраните файл и перезапустите Staffcop:
sudo service staffcop restart
В папке Политики → Анализ контента нажмите на политику Распознавание лиц.
В окне свойств политики поставьте флаг Политика активна.
Перейдите во вкладку Фильтр, нажмите Тип события и поставьте флажок напротив Снимок с веб-камеры.
Нажмите + Файл, выберите Тип контента и поставьте флажки image/jpg и image/png.
Нажмите Сохранить.
После поступления первых результатов распознавания установите для каждого аккаунта соответствие изображения пользователю:
Перейдите в Конструктор → Уведомления и выберите Неизвестное лицо.
Найдите снимок с подходящим освещением и ракурсом анфас — лицом к камере — в таблице событий.
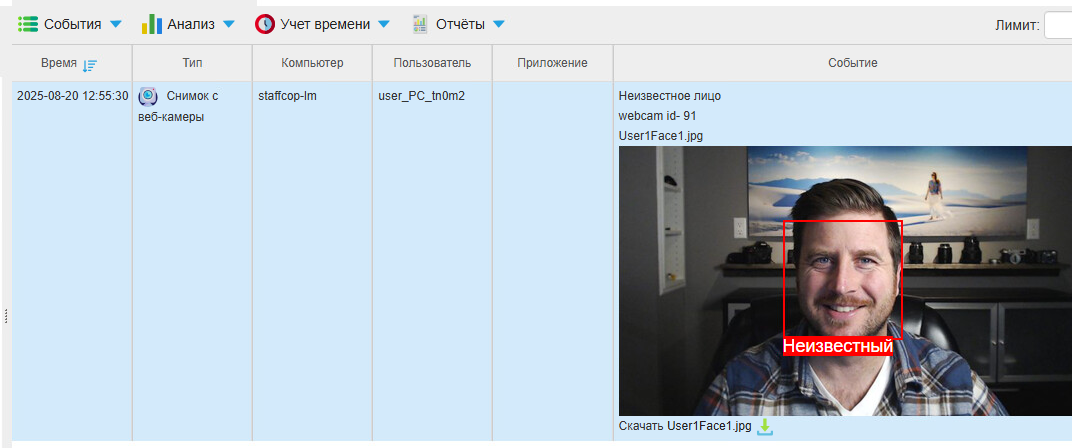
Нажмите на красную рамку с подписью Неизвестный.
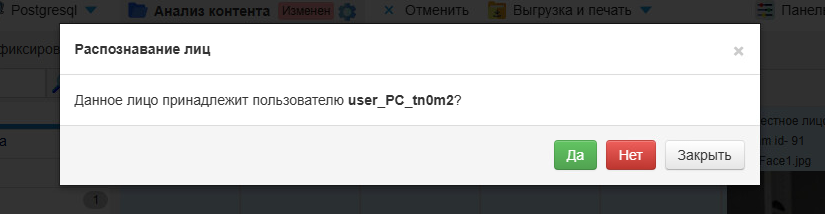
Если лицо соответствует пользователю, ответьте Да на вопрос «Данное лицо принадлежит пользователю TestUser?».
Примечание
При ответе Нет соответствие будет сброшено. Используйте кнопку Закрыть, если случайно открыли это окно или решили ничего не менять.
Изменения в результате установки соответствия будут применяться только к новым событиям. Проверьте, что лица на изображениях соответствуют владельцам компьютеров.
Ложные срабатывания¶
К ложным срабатываниям или полному отсутствию распознавания могут привести поворот головы, несоответствующий ракурс лица, закрытая, например рукой, часть лица.
Чтобы уменьшить вероятность ложных срабатываний:
Откройте файл /usr/share/staffcop/settings.py.
Уменьшите значение параметра FACE_DETECT_THRESHOLD, например:
FACE_DETECT_THRESHOLD = 0.5Примечание
При необходимости параметр можно уменьшать до 0.4, но следует учитывать, что чем меньше значение, тем меньше распознаваний.
Сохраните файл и перезапустите Staffcop:
sudo service staffcop restart
Распознавание лиц на скриншотах и в перехваченных файлах¶
Чтобы распознавать лица не только на снимках веб-камер, но и на скриншотах и в перехваченных файлах:
Откройте файл /usr/share/staffcop/settings.py и добавьте запись:
FACES_TYPES = ( "WebcamSnapshot", "Screenshot", "InterceptedFile")
Перезапустите Staffcop:
sudo service staffcop restart
В папке Политики → Анализ контента откройте настройки политики Распознавание лиц.
В окне свойств перейдите в Фильтры и добавьте события:
Снимок с веб-камеры,
Скриншот,
Перехваченный файл.
Нажмите Сохранить.
Что важно знать:
Система умеет распознавать попытки «заглушить» камеру — заклейку, размытие и т. д.
Трудноразличимые снимки могут создавать алерты Нет снимка. Если их слишком много, обратитесь в техническую поддержку.
Лицо должно занимать не меньше 2,5% кадра.
Размеры нескольких лиц на изображении не должны различаться более чем в 2 раза, иначе распознавание сработает на случайные лица на заднем плане.
Лица не должны перекрывать друг друга. Центр меньшего лица не должен попадать внутрь рамки большего, иначе меньшее лицо не будет распознано.
Одно и то же лицо из базы учитывается только один раз на снимок. Избыточные срабатывания игнорируются.
Алгоритм распознавания — HOG.
Распознавание паспортов¶
Распознает разворот главной страницы паспорта РФ:
в PDF-файлах,
изображениях форматов png и jpeg,
скриншотах.
Примечание
Разворот главной страницы паспорта — страница с информацией о выдаче паспорта и страница с фотографией владельца.
Чтобы включить поиск паспорта РФ:
В папке Политики → Анализ контента нажмите на политику Распознавание паспортов.
В окне настройки политики включите опцию Политика активна.
Перейдите во вкладку Фильтр и при необходимости добавьте ограничения.
Нажмите Сохранить.
При обнаружении паспорта в разделе Сработавшие политики появятся события Паспорт РФ.
Ложные срабатывания¶
При распознавании могут появляться ложноположительные срабатывания, когда событие появилось в Сработавших политиках, но не содержит изображений с паспортом.
Если ложных срабатываний много:
Подключитесь к серверу распознавания и откройте файл /etc/staffcop/cpservice-config.
Добавьте строку PASSPORT_THRESHOLD:
PASSPORT_THRESHOLD = 0.7
Сохраните файл и перезапустите службу командой:
service staffcop-cpservice restart
Логи и отладка работы¶
Сервер распознавания¶
Лог работы сервера распознавания расположен по пути:
/var/log/staffcop-cpservice.log
Пример запроса:
2020-09-10 12:19:39,065 [DEBUG] cp_server:112 Request for 2020_09_10/ae4cd000abaecdaf46eec3d3ac90750d327e688a.jpe : text_extraction face_detection
Где text_extraction и face_detection — опциональные параметры: извлечение текста и распознавание лиц.
Результат обработки:
2020-09-10 12:24:20,125 [DEBUG] cp_server:127 Response for 2020_09_10/9ade404783b02bff8741ed1632ffbf63d883c64e.jpe done in 0:01:04.814513: "document_class": undetected, "face": {'size': {'width': 640, 'height': 480}, 'bounds': [{'top': 306, 'right': 381, 'bottom': 476, 'left': 211}], 'vectors': '...'}, "extracted_text": "
В команде указан тип документа, сэмплы результата обработки лиц и извлечения текста, затраченное на обработку время.
Сервер Staffcop¶
Расположение лога сервера распознавания:
/var/log/staffcop/content_processing.log
Ошибки¶
Сообщение об ошибке указывает на недостаток мест на RAM-диске:
[ERROR] content_processing:420 API error: [Errno28] No space left on device
Ошибка возникает при работе с большими файлами или при большом количестве ядер на сервере. Чтобы ее исправить, увеличьте размер дисковой памяти.
Для увеличения памяти:
Подключитесь к серверу распознавания и откройте файл /etc/staffcop/cpservice-config.
Добавьте строку:
RAMDISK_SIZE = '5G'
Сохраните файл и перезапустите службу командой:
service staffcop-cpservice restart
Примечание
Оптимальный размер RAMDISK_SIZE рассчитывается по формуле: максимальный размер обрабатываемого файла × количество ядер сервера. По умолчанию используется 500 MБ.
Последнее обновление: 05.06.26