Speech-to-text (Распознавание речи)¶
В Staffcop Enterprise начиная с версии 5.X - была добавлена функция - Speech To Text (преобразование записанного звука в текст).
Описание модуля¶
Модуль распознавания звука в текст работает через Tinkoff Speech Kit.
Модуль распознавания звука в текст требует доступа в интернет по адресу - voicekit.tinkoff.ru и api.tinkoff.ai (Адреса находятся в России).
Модуль распознавания голоса от tinkoff разработан компанией Tinkoff (наработки не используют зарубежные технологии и не передают данные дальше дата-центра по обработке голоса Tinkoff).
Модуль поддерживает работу в многопоточном режиме, для одновременной обработки большого количества одновременно распознаваемых аудиоданных.
Оплата за облачный модуль распознавания речи в текст - осуществляется через личный кабинет на сайте - voicekit.tinkoff.ru
Стартовый ознакомительный баланс на счету от Tinkoff Speech Kit - составляет - 1000р., что позволяет распознать порядка 92.5 часов голосовых записей.
Включение модуля¶
Для активации модуля распознавания звука в текст, нужно проделать несколько действий:
Пройти регистрацию на сайте - Tinkoff Speech Kit, кликнув в верхнем правом углу - «Войти» и заполнить форму e-mail и телефон.
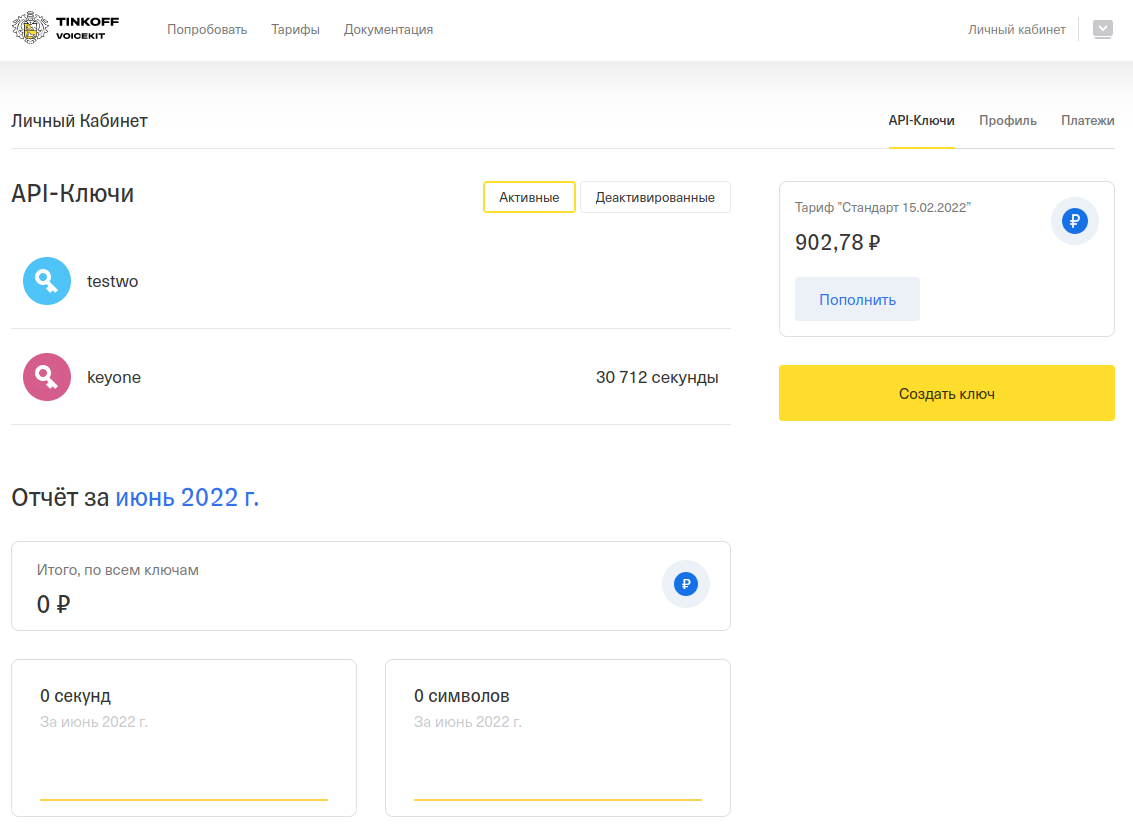
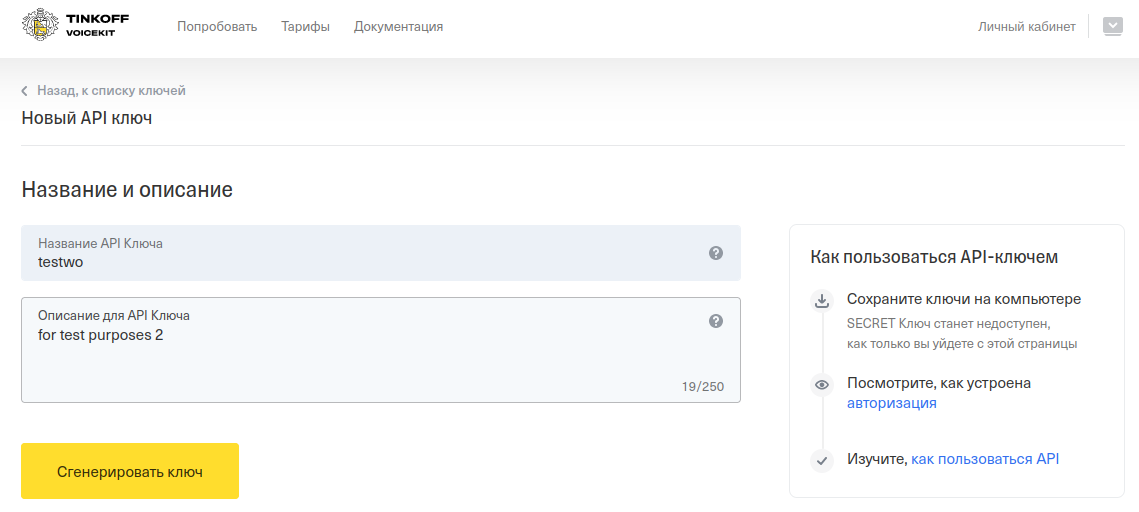
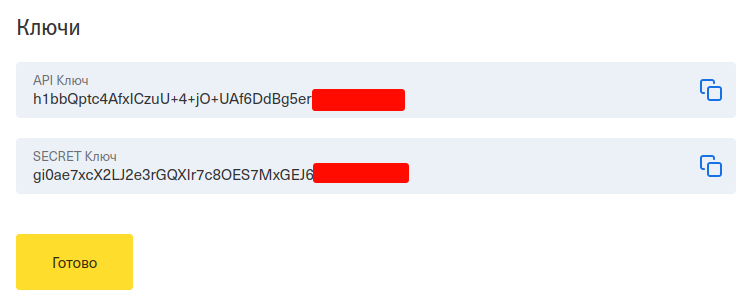
Сгенерировать «API-key» и «Secret-key», скопировать их.
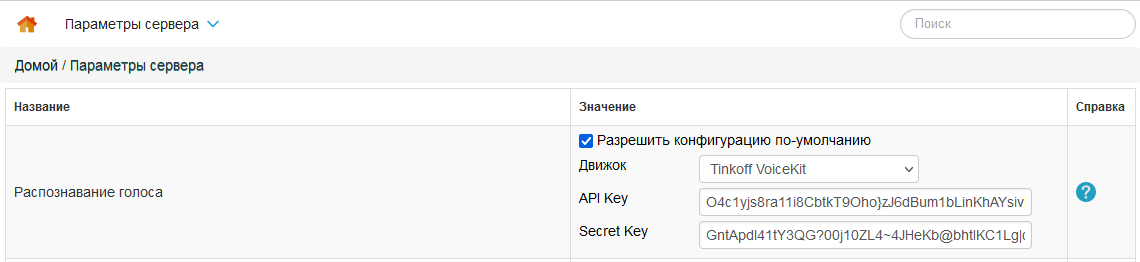
Открыть веб-интерфейс Staffcop и перейти на страницу «Панель управления - Параметра сервера - Распознавание голоса». Поставить галочку «Разрешить конфигурацию по-умолчанию», внести параметры и выбрать движок - «Tinkoff VoiceKit», после сохранить изменения в параметрах сервера.
Работа модуля¶
Для распознавания речи в текст служат два механизма:
Распознавание под записями звука, в виде кнопки «Распознавание речи»

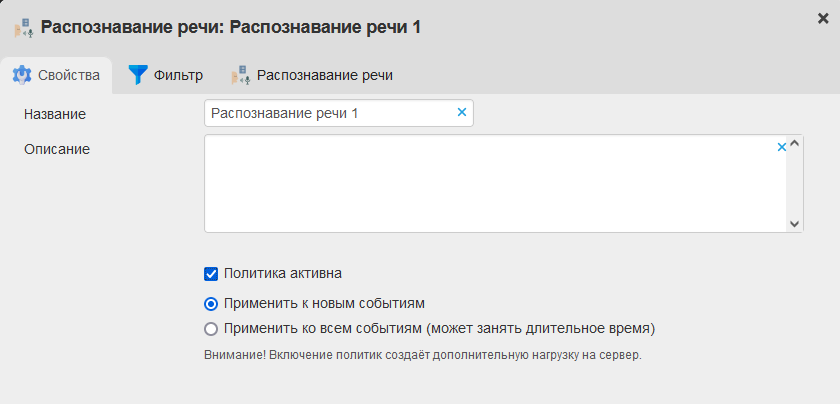
Распознавание через политику - «Распознавание речи»
Первый способ распознавания: через иконку под записями звука.
Нужен для демонстрации технологии и проверки работы. После клика на значок, будет распознан указанный фрагмент звуковой записи в текст (если таковой будет обнаружен в отрезке записи).
Второй способ распознавания: через политику «распознавание речи» - более общий.
Позволяет распознавать голос в текст на общем основании и накапливать текстовую базу преобразования голоса в текст и анализировать данные с помощью встроенных политик распознавания по словарям, регулярным выражениям и встроенным политикам безопасности, т.е. после отработки политики «Распознавание речи», будут отработаны стандартные политики обработки текста в Staffcop. Добавить политику можно нажав в web-интерфейсе «Создать -> Распознавание речи». В подменю политики «Распознавание речи» будет доступна отладочная информация и статистика по анализу речи за всё время работы политики.
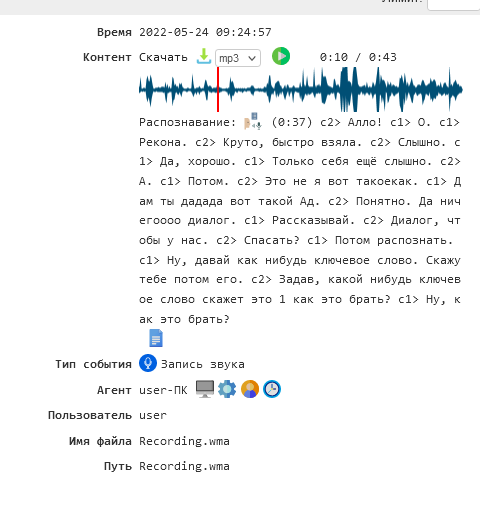
Речь записанная модулем «записи и микрофона и колонок» - может определяться как «диалог», т.е. распознанная речь теперь имеет двух собеседников.
Пример такой работы:
Особенности работы и примечания¶
Модуль Speech To Text спроектирован для будущего развития и возможности подключить встроенный в Staffcop - модуль распознавания на основе моделей определения голоса и для подключения других сторонних технологий распознавания.
Файлы конвертируются в моно mp3, размер при этом изменяется не существенно.
Наибольшая замеченная скорость распознавания равна x15 (время распознавания равно 1/15 от продолжительности записи), например, за сутки записано 470 часов, тогда 470/15=31 час, т.е. требуется 31 час, чтобы распознать записи сделанные за 24 часа (значит распознавание, в данном примере, всегда будет отставать от записи, придётся настраивать фильтрацию, например, по устройствам или по пользователям).
Для примера выше - 470 часов записей, по самому низкому тарифу Tinkoff-а, обойдутся в 5076р.
«Обычно» количество «мусора» колеблется от очень много до очень-очень много. Под «мусором» подразумеваются записанные системные звуки, работающий телевизор, разговоры в комнате (удалёнка) и пр.
В процессе работы собирается статистическая информация, например, продолжительность аудио и время его обработки (конвертирование + распознавание).
Временные файлы хранятся в /var/lib/staffcop/upload/speech_recognition/…
Все результаты работы подсистемы сохраняются в дополнительных таблицах speechrecognition_result (модель speech_processing.models.SpeechRecognitionResult) и speechrecognition_failure (модель speech_processing.models.SpeechRecognitionFailure) и на данный момент их чистка не предусмотрена.
Наличие таблицы «speechrecognition_result» облегчает повторные проходы, например, если результаты работы успешные, то обрабатываться будут только записи с ошибками, пропущенные или не обработанные ранее.
Количество попыток распознания ограничено, оно сейчас никак не конфигурируется (см. speech_processing.config:Config.attempts_limit) и равно 5.
При большом количестве ошибок (например, неправильный ключ доступа к сервису распознавания, ошибка сети и т.д.), политика будет отключена.
После удачного распознавания нормализованные аудио удаляются, в противном случае - нет. Чистка ФС от нормализованных аудио не реализована.
Cуществует «костыль» от коротких файлов в виде предварительной проверки размера файла, файл не должен быть меньше 30kB (ориентировочная продолжительность такой записи до 2 сек).
Существует «костыль» и для защиты от больших файлов (сделано из-за Tinkoff, см. выше, но применяется ко всем «движкам»), файл не должен быть больше 30MB.
Распознавание on-demand (руками) и через политики происходит разными методами: ручной вариант имеет больший приоритет и стоит дороже (по текущему тарифу, этот механизм называется - «Онлайн-обработка файла» и стоит 0.48руб/мин) для политик применяется более дешёвый механизм - «Отложенная обработка» (по текущему тарифу это стоит 0.18руб/мин).
Файлы размером более 32MB должны загружаться через собственный API S3 и такой функционал в данной подсистеме не реализован (для ориентира: 10 минут записи весит около 5MB).
Чит-коды и работа из консоли сервера¶
В linux-консоли севера Staffcop - существуют несколько команд служащих для оценки количества данных и для запуска политики распознавания вручную.
Команда «sr_estimate»
Предназначена для оценки объёмов записей (количество и размер файлов, продолжительность аудио).
Для работы команды требуется, что бы предварительно была создана политика SpeechRecognitionPolicy (см. sr_mule ниже). Задать политику нельзя, будет выбрана одна из доступных произвольным образом.
Пример использования:
$ time staffcop sr_estimate --force --from-event=2021-12-01
Thread pool size: 3
2021-12-01: (745+41/786) duration:8.2h size:227m
2021-12-02: (0+49/49) duration:0m size:0m
2021-12-03: (0+37/37) duration:0m size:0m
2021-12-04: (0+1/1) duration:0m size:0m
2021-12-06: (0+24/24) duration:0m size:0m
2021-12-07: (0+23/23) duration:0m size:0m
2021-12-08: (0+17/17) duration:0m size:0m
2021-12-09: (0+74/74) duration:0m size:0m
2021-12-10: (53+0/53) duration:3m size:1m
real 1m4.300s
user 0m43.485s
sys 0m16.063s
Параметры:
–force – обрабатывать все события политики включая те, которые были успешно «распакованы» ранее, например при использовании команды sr_mule
–threads – число потоков
–from-event – идентификатор или дата (в формате YYYY-MM-DD) события, начиная с которого будет происходить обработка
–to-event – идентификатор или дата события, до которого (но не включая его) будет происходить обработка
Команда «sr_mule»
Предназначена для запуска mule в консольном режиме с предварительной настройкой некоторых параметров.
При первом запуске будет создана политика SpeechRecognitionPolicy, если в базе нет ни одной такой политики. Если политик несколько, по аналогии с sr_estimate, будет выбрана произвольная.
Пример первого запуска для создания политики:
$ staffcop sr_mule --to-event=0
Process #13448 has unsafe gevent patches, try to reexec
[Errno 9] fd:11
Server exit after 0.1s of work
Параметры:
–debug – вывод отладочной информации (без этого ключа будет очень скучно, рекомендую к использованию всегда)
–force – обрабатывать все события политики включая те, которые были успешно «распакованы» ранее, например при использовании команды sr_mule
–simulate – не отправляет аудио на сервер Tinkoff-а, вместо этого в результаты подставляется случайный текст (используется для отладки)
–keep-normal-audio – сохраняет перекодированное аудио после распознавания, оно будет использовано при повторных запусках (опять же, нужно в первую для отладки), это аудио так же сохраняется в случае ошибок в процессе распознавания
–threads – число потоков, которые будут использоваться для кодирования и отправки аудио на внешний сервер (по-умолчанию 10)
–watch-threads – число потоков, которые будут использоваться для получения результатов (по-умолчанию 3)
–bucket-size – размер пакета (число событий) для параллельной обработки (по-умолчанию 50)
–from-event – идентификатор или дата (в формате YYYY-MM-DD) события, начиная с которого будет происходить обработка
–to-event – идентификатор или дата события, до которого (но не включая его) будет происходить обработка
Ещё один пример:
$ staffcop sr_mule --force --debug --simulate --keep-normal-audio --from-event=2021-12-10
Process #14011 has unsafe gevent patches, try to reexec
[Errno 9] fd:11
Starting <TinkoffRecognitionEngine at 0x7fa12880ddd0>...
Loop step (tasks:0 threads:0+0)
Recognize speech for #3602820
Recognize speech for #3603717
Recognize simulation #3602820 (0.8s)
[...]
Loop step (tasks:1 threads:1+0 RECOGNITION:1)
Recognition result #3606172: (6.0s) "Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur."
Save result for #3606172 (74.4s)
Loop step (tasks:0 threads:0+0)
Loop step (tasks:0 threads:0+0)
Loop step (tasks:0 threads:0+0)
Loop step (tasks:0 threads:0+0)
Loop step (tasks:0 threads:0+0)
Loop step (tasks:0 threads:0+0)
Loop step (tasks:0 threads:0+0)
Server exit after 7.6s of work
Shutdown <TinkoffRecognitionEngine at 0x7fa12880ddd0>...
Конфигурирование модуля из файла конфигурации сервера
В локальной конфигурации сервера /etc/staffcop/config - возможно задать ключи для работы сервера распознавания Tinkoff вручную:
TINKOFF_API_KEY = „…“ - ключи полученные из Tinkoff SpeechKit.
TINKOFF_SECRET_KEY = „…“ - ключи полученные из Tinkoff SpeechKit.
SPEECH_RECOGNITION_DEBUG - добавляет отладочной информации в логи.
SPEECH_RECOGNITION_AUDIO_DURATION_MIN - нижний порог продолжительности исходного аудио в сек. (по-умолчанию 3), записи меньшей продолжительностью будут пропущены с ошибкой [AudioDurationError].
TINKOFF_JWT_EXPIRATION - время устаревания JWT-токена используемого в API Tinkoff в сек. (по-умолчанию 600).
SPEECH_RECOGNITION_ATTEMPTS_LIMIT - максимальное количество попыток распознавания (по-умолчанию 5).
SPEECH_RECOGNITION_NORMAL_CMDLINE (по умолчанию - «ffmpeg -y -v 16 -i $source_file -map_metadata -1 -map 0:a:0 -ac 1 -aq 3 $normal_file») - Запись с одного устройства - одна дорожка в исходном аудио. В результате конвертации будет моно.
SPEECH_RECOGNITION_NORMAL2_CMDLINE (по умолчанию - «ffmpeg -y -v 16 -i $source_file -map_metadata -1 -filter_complex «[0:a]amerge=inputs=2,pan=stereo|FL<c0+c1|FR<c2+c3» -aq 3 $normal_file») - Запись с двух устройств - две дорожки в исходном аудио. В результате конвертации будет стерео, а результат распознавания будет интерпретироваться как диалог.
Обработка ошибок¶
После обработки группы событий из выборки размерностью POLICY_BATCH (см. settings.py, по-умолчанию 10000, выборка происходит по Event.id, так что считать нужно все события, а не только отфильтрованные «звуковые», это стандартный механизм мулов) в данных политики сохраняется информация о необходимости выполнить повторную обработку (см. SpeechRecognition.data_dict[„restore_attempts“], _schedule_restore_attempts и _restore_attempt)
Эта повторная обработка выполняется перед следующей итерацией политики, т.е. при обработке следующей выборки размерностью POLICY_BATCH,
Важное замечание: если этой итерации нет (все события обработались на предыдущем шаге и новых событий в БД нет), то и попытки восстановления не будет (до тех пор, пока не появятся новые данные)
При выборе в настройках политики «Apply to all events (can take long time)» (применить ко всем событиям), «restore_attempts» - сбрасывается.
При большом количестве ошибок (~ >= 66% на 150 отфильтрованных событий) - политика будет отключена, но что бы увидеть это в интерфейсе, веб-страницу придётся обновить, если она была открыта ранее (речь об основном одностраничном интерфейсе).