Мониторинг состояния сервера¶
С версии 5.7.4 в Staffcop произошла замена системы мониторинга сервера. Вместо InfluxDB и Telegraf для сбора данных теперь используется стек Prometheus + Grafana + Node Exporter.
Как и раньше, сервис предоставляет администратору доступ к визуальному представлению нагрузки на сервер.
Для работы с мониторингом перейдите на новый стек.
Порядок действий при переходе:
Убедитесь, что новый мониторинг работает и отображает актуальные данные.
Внимание
При обновлении сервера старые сервисы InfluxDB и Telegraf автоматически не удаляются. Миграция накопленных данных мониторинга не предусмотрена. При удалении influxDB и Telegraf вся информация по состоянию сервера будет удалена. Перед удалением убедитесь, что вы полностью перешли на Prometheus и исторические данные вам больше не нужны.
Если у вас установлен какой-то кастомный пакет Prometheus, удалите его. При возникновении вопросов обратитесь в техническую поддержку.
При необходимости настройте масштабирование для получения метрик с дополнительных серверов.
Если вы еще используете старую версию или только планируете обновление, для управления старыми сервисами используйте стандартные команды systemctl:
# Проверка статуса старых сервисов
systemctl status influxdb
systemctl status telegraf
# Проверка статуса Grafana
systemctl status grafana-server
Установка системы мониторинга¶
Для вашего удобства мы подготовили универсальный скрипт, который автоматически установит все компоненты системы мониторинга.
Скачайте скрипт на компьютер с выходом в Grafana и выдайте права на выполнение:
wget https://distr.staffcop.su/docs-assets/grafana/monitoring_install.sh && chmod +x monitoring_install.sh
Запустите скрипт:
sudo ./monitoring_install.sh
Скрипт установит сервисы системы мониторинга:
Prometheus,
Node Exporter,
Grafana.
Если Grafana уже установлена на сервере, скрипт обновит ее до последней доступной версии.
После выполнения скрипта сервисы готовы к работе. Проверить работоспособность сервисов можно командами:
systemctl status prometheus
systemctl status node-exporter
systemctl status grafana-server
Внимание
По умолчанию данные хранятся в Prometheus 80 дней. Для изменения длительности хранения отредактируйте в Systemd в юните /etc/systemd/system/prometheus.service параметр storage.tsdb.retention.time.
Настройка Grafana¶
Вход в Grafana¶
Чтобы зайти в Grafana, откройте браузер и перейдите по адресу:
http://<ip-адрес-вашего-сервера>:3000
где 3000 — номер порта, на который устанавливается сервис.
Используйте:
логин: admin,
пароль: admin.
Подключение Prometheus¶
После входа в Grafana подключите Prometheus как источник данных.
Перейдите во вкладку Connections → Data sources.
Нажмите кнопку + Add new data source.
В интерактивном меню выберите Prometheus.
В поле Prometheus server URL укажите:
http://localhost:9090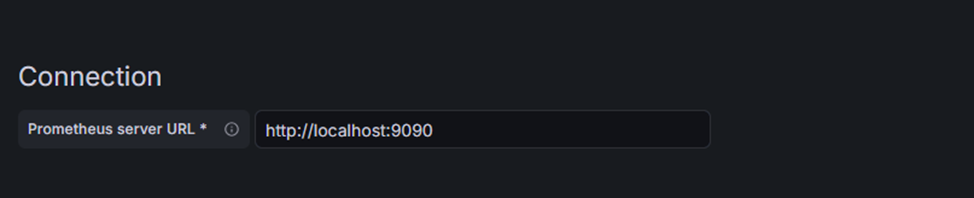
Прокрутите страницу вниз и нажмите кнопку Save & test.
В результате должно появиться зеленое уведомление: Successfully queried the Prometheus API. Это означает, что связь между Grafana и Prometheus установлена.

Импорт готового дашборда¶
Чтобы не создавать графики вручную, мы подготовили готовый дашборд.
Скачайте дашборд по ссылке:
https://distr.staffcop.su/docs-assets/grafana/staffcop_node_exporter_dashboard.json
В Grafana перейдите во вкладку Dashboard.
Нажмите кнопку New → Import.

Загрузите скачанный дашборд.
Опционально: измените имя и папку.
В поле Select a Prometheus data source выберите источник данных Prometheus.
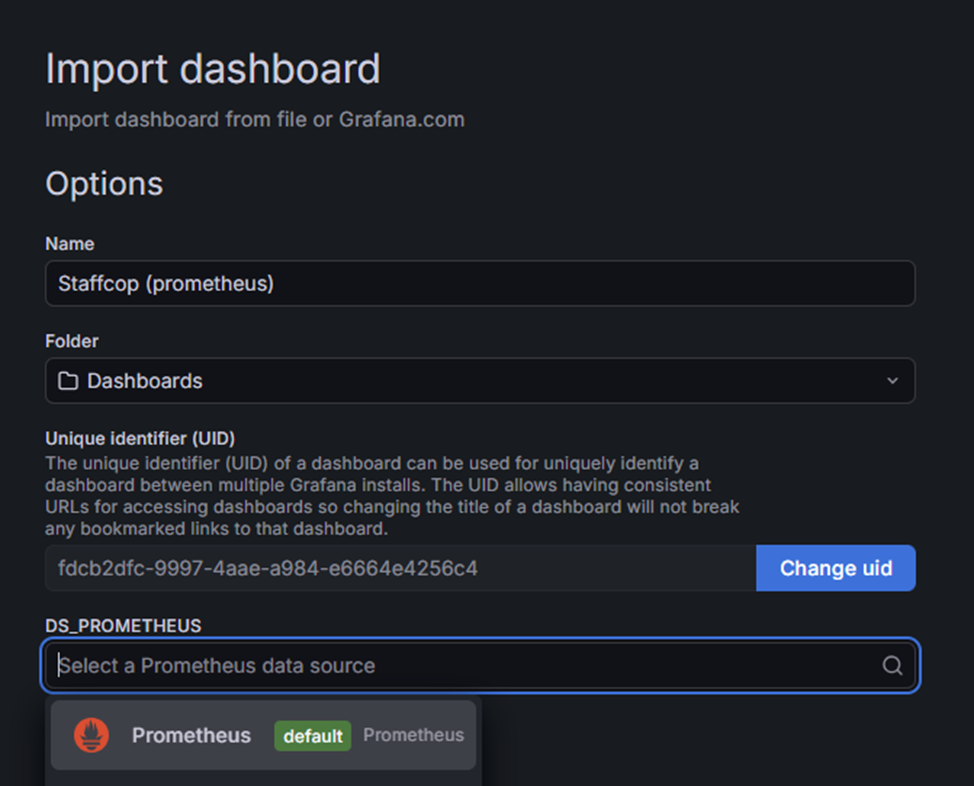
Нажмите Import.
После выполнения шагов импортированный дашбород будет доступен для просмотра.
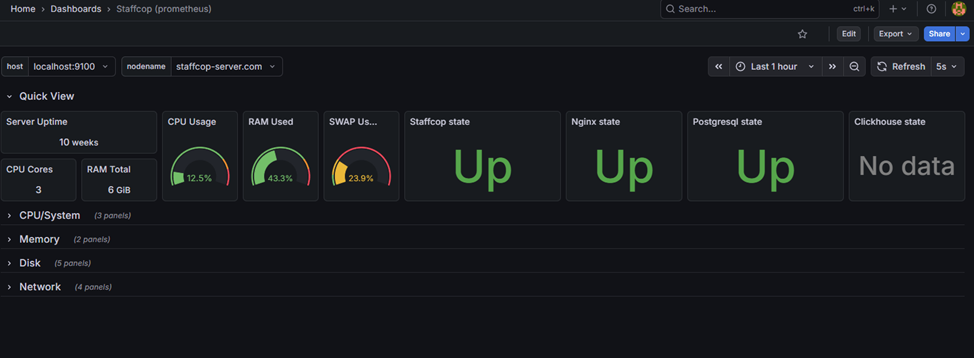
Для удобства работы метрики разделены на несколько панелей:
Quick View — общее состояние сервера и служб;
CPU/System — нагрузка на CPU, общая нагрузка на сервер, процент использования дисков;
Memory — количество использованной RAM и вызывов OOM;
Disk — нагрузка на диски, количество IOps, утилизация дисков и др.;
Network — нагрузка на сеть.
Подробную справку о метрике вы можете получить, наведя курсор на значок i справа от ее названия.
В случае возникновения вопросов обращайтесь в техническую поддержку.
Удаление influxDB и Telegraf¶
Опасно
В предыдущей системе мониторинга сервера использовались influxDB и Telegraf. Если вы работали с этими сервисами и перешли на Prometheus, удалите их, чтобы не вызывать лишнюю нагрузку на систему. Накопленные ранее данные о состоянии системы будут удалены.
Чтобы удалить influxDB и Telegraf, выполните:
Выключите сервисы:
sudo systemctl stop influxdb sudo systemctl stop telegraf
Удалите пакеты:
sudo apt-get remove --purge influxdb telegraf
Удалите оставшиеся файлы конфигураций и директории с данными:
sudo rm -rf /var/lib/influxdb sudo rm -rf /etc/telegraf
Удалите старые панели мониторинга (dashboard) и источники данных influxDB (datasource).
sudo rm /etc/grafana/provisioning/datasources/grafana-datasource.yaml sudo rm /etc/grafana/provisioning/dashboards/default.yaml sudo rm -rf /etc/grafana/provisioning/staffcop
Перезапустите Grafana:
systemctl restart grafana-server
Последнее обновление: 05.06.26