Cервер распознавания графических объектов¶
Описание и возможности¶
Сервер распознавания устанавливается на отдельную от сервера Staffcop Enterprise (виртуальную) машину. В состав сервера входит несколько движков, которые извлекают данные и обнаруживают графические сущности в документах.
Возможности сервера распознавания:
обнаружение печатей на изображениях по заданному образцу: скан-копии, скриншоты, фотографии документов с оттиском печати;
обнаружение изображений паспорта гражданина России: скан-копии, скриншоты, фотографии главной страницы;
распознавание лиц и создание оповещений по результатам распознавания;
распознавание больших объёмов текста, в том числе текста с любых изображений (скан-копии, скриншоты, фотографии) или из файлов-контейнеров (например, формата pdf или в zip);
работа с наиболее популярными форматами хранения изображений: png, jpeg, jpg, jpe, pdf.
Установка сервера¶
Для работы анализатора графических объектов установите дополнительные пакеты:
sudo apt update && sudo apt upgrade
sudo apt install software-properties-common
# установите python3.7
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt install python3.7
sudo apt install python3.7-venv
# установите оставшиеся пакеты
sudo apt install -y libpoppler-cpp0v5 poppler-utils libsm6 tesseract-ocr
Добавьте репозиторий Staffcop в список репозиториев системы и установите сервер распознавания при помощи apt:
wget -O - http://distr.staffcop.su/stable5.4/staffcop.gpg | sudo apt-key add -
echo "deb http://distr.staffcop.su/stable5.4 stable5.4 non-free" | sudo tee /etc/apt/sources.list.d/staffcop.list
sudo apt update
sudo apt install staffcop-cpservice
Общий размер пакета около 850 МБ — при низкой скорости доступа в Интернет скачивание может занять длительное время.
На этом установка программного обеспечения завершена.
Настройка на стороне сервера Staffcop Enterprise¶
Перед настройкой модуля Анализ контента включите доступ к API сервера в параметрах сервера Staffcop Enterprise:
Зайдите в основном интерфейсе в Панель управления → Параметры сервера:
Выберите Доступ к API разрешён.
Поставьте флажок в чекбоксе Значение и нажмите Сохранить. Значение параметра Доступ к API разрешён изменится на Да.
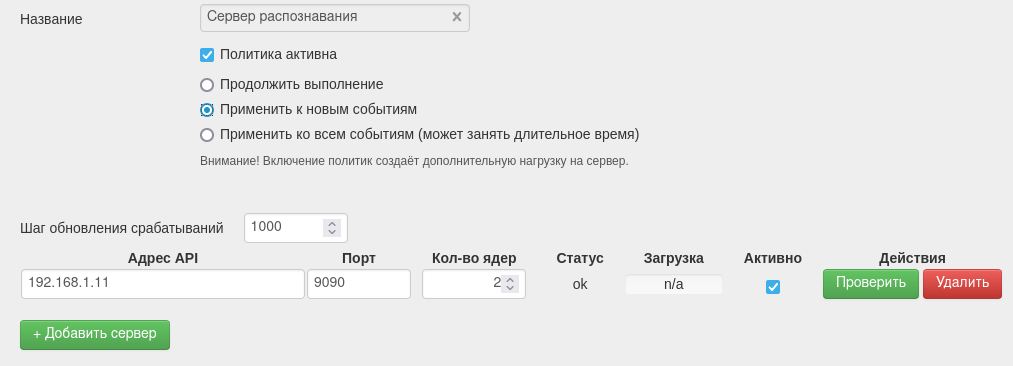
Во вкладке Политики перейдите в Политики → Системные политики → Сервер распознавания.
Добавьте в поля данные машины, на которой установлен сервер распознавания:
Шаг обновления срабатываний — количество событий, которое обрабатывает сервер распознавания за один раз. Чем меньше это число, тем чаще будет происходить обновление. Оптимальное значение параметра — 10 000. Если строка пустая, значение также принимается равным 10 000. Не устанавливайте значения меньше 10 000, чтобы не увеличивать нагрузку на сервер.
Адрес API — доменное имя или IP-адрес сервера распознавания.
Порт — порт доступа к серверу распознавания. По умолчанию — 9090.
Кол-во ядер — должно соответствовать числу ядер сервера модуля.
Статус — наличие связи с сервером.
Загрузка — нагрузка на сервер распознавания.
Активно — включение/выключение сервера распознавания.
Поставьте галочку Политика активна и сохраните изменения.
Настройка модуля Анализ контента¶
Подключитесь к серверу распознавания по SSH. Откройте конфигурационный файл сервера в текстовом редакторе:
sudo nano /etc/staffcop/cpservice-config
И укажите параметры:
PORT = 9090
SERVER_ADDR = 'http://192.168.1.x'
SECRET = 'xxxxxxxxxxxxxxxx'
Сохраните изменения и перезапустите сервер командой:
sudo service staffcop-cpservice restart
Готово! Сервер настроен.
Политики распознавания контента¶
Настраиваются на сервере Staffcop в веб-интерфейсе.
Время на обработку изображений:
Формат изображения |
Время на обработку, с |
full HD изображение без поворота |
5 |
4K изображение |
20 |
изображение печати, паспорта, картинки в формате JPEG |
4—6 |
распознавание лица |
5—60 |
Анализ контента¶
В разделе Фильтры перейдите во вкладку Политики, далее в папке Политики выберите Анализ контента.
Сервер распознает:
текст,
речь,
печати,
лица,
паспорт РФ.
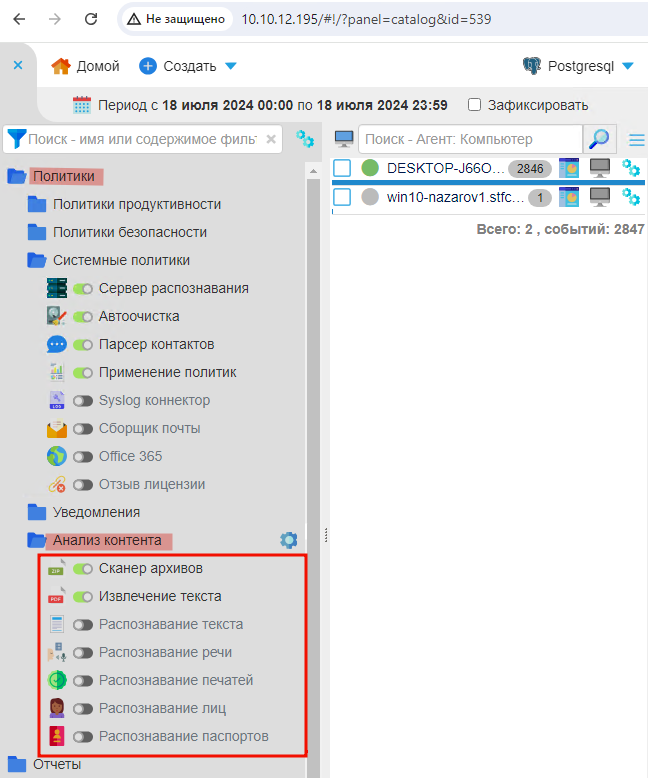
Кроме этого, в Анализе контента доступны опции:
Извлечение текста — сохраняет текстовое содержимое из события Перехаченный файл.
Сканер архивов — создает событие Перехваченный файл из файлов перехваченного архива.
Распознавание текста¶
Позволяет распознавать текст на изображениях.
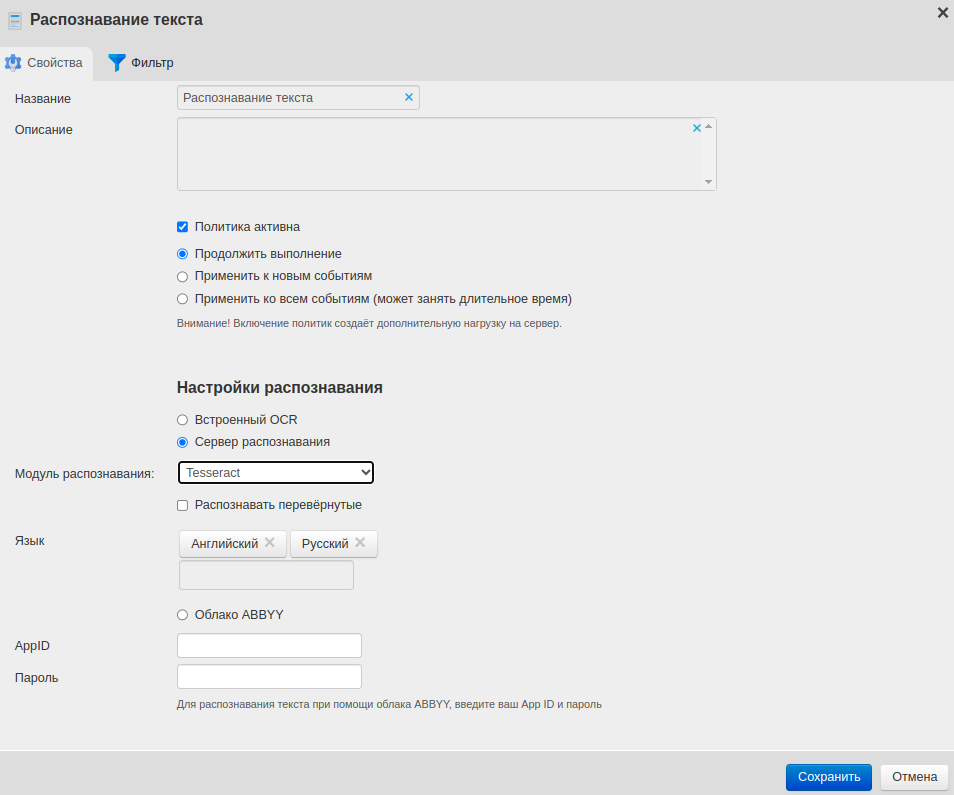
Вкладка Свойства содержит настройки распознавания текста:
Встроенный OCR / Сервер распознавания — выбор инструмента распознавания. Кроме сервера распознавания, вы можете использовать встроенный OCR. Подробнее — в статье Настройка модуля OCR.
Модуль распознавания — движок для распознавания.
Tesseract. Бесплатная библиотека для базового OCR, простая и гибкая.
Content AI ABBYY. Платный движок, требует дополнительных настроек на сервере и платной лицензии с компонентом OCR. Обеспечивает высокую точность, лучше распознает перевернутые изображения.
Распознавать перевёрнутые — распознавание текста на перевёрнутых изображениях. Опция расширяет возможности, но нагружает сервер распознавания.
Язык — языки для распознавания: русский, английский.
Облако ABBYY — если у вас есть аккаунт на облачном сервисе ABBYY, вы можете его подключить. Просто введите свой логин и пароль.
Во вкладке Фильтр можно настроить фильтр для политики распознавания текста.
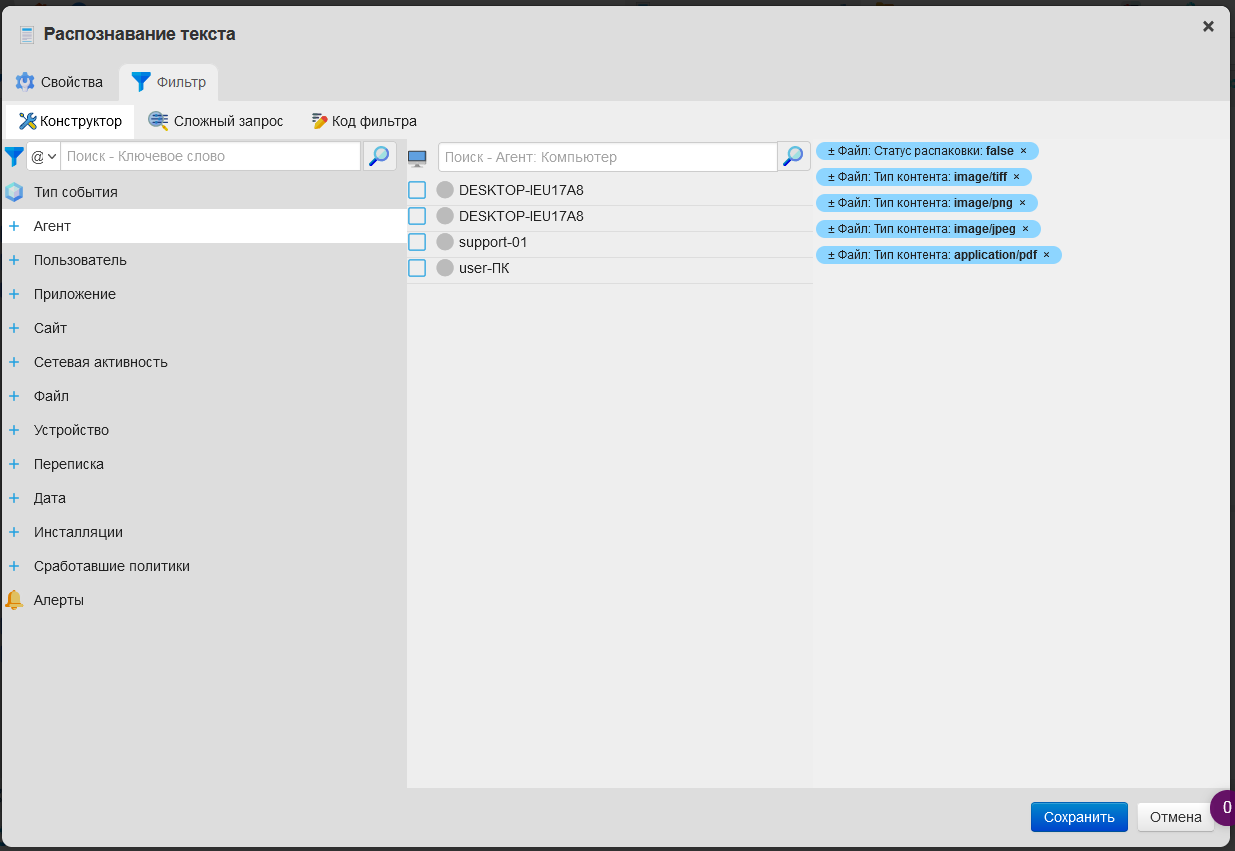
Настроенный по умолчанию фильтр выглядит так:
agent_attachedfile@mime:mime=application/pdf
agent_attachedfile@mime:mime=image/jpeg
agent_attachedfile@mime:mime=image/png
agent_attachedfile@mime:mime=image/tiff
agent_attachedfile@extracted:extracted=false
agent_eventtype@default:agent_eventtype=0#Intercepted file
{
"operator": "AND",
"rules": []
}
Распознавание речи¶
Переводит аудиозаписи в текст. Подробнее — в статье Распознавание речи.
Распознавание печатей¶
Примечание
На данный момент поддерживается поиск только круглых печатей.
Сервер распознаваний находит изображения печати по заданным образцам в документах формата jpg, jpe, jpeg, png и pdf.
Примечание
На данный момент политику можно создать только одну политику для одной печати. Если у вас несколько печатей, обратитесь в техподдержку.
Для работы политики понадобятся образцы печатей — фрагменты изображений, на котором содержится печать. Окружающий текст и подписи не являются помехами для распознавания. Чтобы повысить качество распознавания используйте несколько образцов печати.
Что важно для таких образцов:
размер изображения — 400x400px;
разная степень нажатия при печати;
небольшие различия между образцами;
отсутствие бракованных оттисков;
расположение печатей под разными углами.
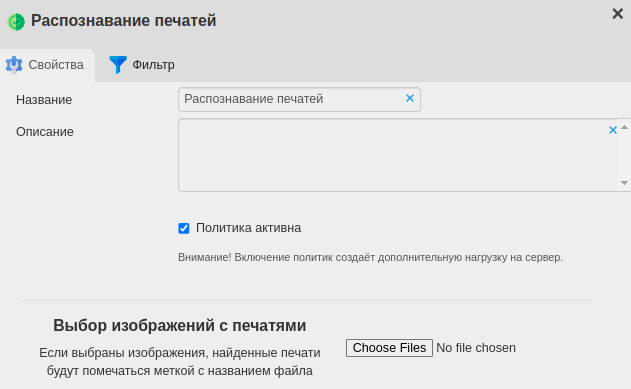
Чтобы создать политику распознавания для печати:
Перейдите во вкладке Политики в папку Политики → Анализ контента.
Сдвиньте переключатель Распознавание печатей вправо.
Загрузите образец печати через кнопку выбора файла в Выбор изображений с печатями; дождитесь, пока у распознанных печатей в столбце Статус появится галочка.
Задайте фильтр для политики. Например:
Типы контента — pdf, jpg, png;
Типы события — перехваченные файлы/скриншоты.
Примечание
Политика не работает с пустыми фильтрами. Не пропускайте этот шаг.
Установите галочку Политика активна для активации политики. Найденные факты будет доступны в разделе Сработавшие политики.
Ложные срабатывания¶
Для любой политики распознавания образов существует вероятность ложного срабатывания. Чаще всего такое происходит с печатями, имеющими определённое сходство. Чтобы снизить количество ложных срабатываний, откройте конфигурационный файл сервера Staffcop:
sudo nano /usr/share/staffcop/settings.py
и измените значения параметра STAMP_RECOGNITION_THRESHOLD в сторону уменьшения.
Ложные срабатывания возможны, когда компания или организация имеют похожие печати, отличающиеся названием отдела или кодом подразделения. В этом случае обратитесь в нашу техническую поддержку.
Распознавание лиц¶
Сервер распознавания содержит функцию распознавания лиц на снимках веб-камер. Результат распознавания фиксируется в виде соответствующего уведомления: Нет лица, Cвое лицо, Неизвестное лицо, Несколько лиц. Своё и неизвестное лица определяются по заранее назначенным в веб-консоли снимкам их владельцев.
Чтобы включить распознавание лиц:
Перейдите во вкладку Политики, далее — в папку Политики → Анализ контента.
Сдвиньте переключатель Распознавание лиц вправо.
Поставьте галочку Политика активна.
Перейдите во вкладку Фильтр, нажмите Тип события и поставьте флажок напротив Снимок с веб-камеры.
Нажмите + Файл, выберите Тип контента и поставьте флажки image/jpg и image/png.
После поступления первых результатов распознавания установите для каждого аккаунта соответствие изображения пользователю:
Выберите снимок с подходящим освещением и ракурсом анфас (лицом к камере) в таблице событий.
Нажмите на фотографию, откроется диалоговое окно.
Если лицо соответствует аккаунту, ответьте Да на вопрос Распознавание лиц: Данное лицо принадлежит пользователю N.
Примечание
При ответе Нет ранее установленное соответствие будет сброшено. Используйте кнопку Закрыть, если случайно открыли это окно или решили ничего не менять.
Изменения в результате установки соответствия будут применяться только к новым событиям. Проверьте, что лица на изображениях соответствуют владельцам компьютеров.
Алерты в Конструкторе для распознавания лиц:
Алерт |
Описание |
Нет лица |
Лица не обнаружены. |
Своё лицо |
Обнаружено лицо. Это лицо владельца ПК. |
Неизвестное лицо |
Обнаружено лицо. Этого лица нет в базе. |
Несколько лиц |
На снимке присутствует несколько лиц. |
Нет снимка |
Снимок нечитаемый: темнота, отсутствие резкости… |
Ложные срабатывания¶
К ложным срабатываниям или полному отсутствию распознавания могут привести поворот головы, несоответствующий ракурс лица, закрытая, например рукой, часть лица. Повлиять на результат распознавания можно, уменьшив параметр FACE_DETECT_THRESHOLD в /usr/share/staffcop/settings.py:
FACE_DETECT_THRESHOLD = 0.5
Примечание
При необходимости параметр можно уменьшать до 0.4, но следует учитывать, что чем меньше значение, тем меньше распознаваний.
Распознавание иных изображений, кроме снимков веб-камер¶
Чтобы распознать лица не только на снимках веб-камер, в фильтре политики Распознавание лиц выберите подходящие критерии. В /usr/share/staffcop/settings.py добавьте запись:
FACES_TYPES = ( "WebcamSnapshot", "Screenshot", "InterceptedFile")
и перезапустите Staffcop:
sudo service staffcop restart
Дополнительные особенности функции распознавания лиц:
Присутствует проверка на «заглушенные камеры» — заклеенные камеры, сбитая резкость и т. д. В срабатывания так же могут попадать трудно различимые для компьютерного зрения изображения, темнота и подобное. Если в алерте Нет снимка часто происходят нежелательные срабатывания, обратитесь в техническую поддержку.
Площадь лица для корректного распознавания должна составлять не менее 2,5 % от площади изображения.
При распознавании нескольких лиц их размеры не должны отличаться друг от друга более, чем в два раза. Это исключит срабатывание на случайно попавшие в поле зрения камеры лица вдалеке.
Лица не должны пересекаться. Центр меньшего лица не должен лежать внутри рамки большего, в противном случае меньшее лицо игнорируется.
Одно и то же лицо из базы не может распознаться на изображении более одного раза. Избыточные срабатывания игнорируются.
Алгоритм распознавания лиц — HOG.
Паспорт РФ¶
Сервер распознаваний позволяет распознавать разворот главной страницы паспорта РФ в PDF-файлах, изображениях форматов png и jpeg, скриншотах.
Разворот главной страницы паспорта — страница с информацией о выдаче паспорта и страница с фотографией владельца.
Чтобы включить поиск паспорта РФ:
Перейдите во вкладку Политики, далее — в папку Политики → Анализ контента.
Сдвиньте переключатель Паспорт РФ вправо, откроется окно.
Перейдите во вкладку Фильтр и выберите критерии фильтра: тип события, тип контента и т. д.
В результате в Сработавших политиках будут появляться события, подпадающие под установленные критерии.
Ложные срабатывания¶
При распознавании могут появляться ложноположительные срабатывания, когда событие появилось в Сработавших политиках, но не содержит изображений с паспортом. Вероятность таких событий очень низка. Пожалуйста, передайте такие изображения вашему менеджеру или техподдержке.
Если ложных срабатываний много, подключитесь к серверу распознавания и в файле /etc/staffcop/cpservice-config добавьте строку PASSPORT_THRESHOLD:
PASSPORT_THRESHOLD = 0.7
Логи¶
Сервер распознавания¶
Лог расположен по адресу: /var/log/staffcop-cpservice.log.
Запрос и его опции:
2020-09-10 12:19:39,065 [DEBUG] cp_server:112 Request for 2020_09_10/ae4cd000abaecdaf46eec3d3ac90750d327e688a.jpe : text_extraction face_detection
Где text_extraction face_detection — опциональные параметры, извлечение текста и распознавание лиц.
Результат обработки:
2020-09-10 12:24:20,125 [DEBUG] cp_server:127 Response for 2020_09_10/9ade404783b02bff8741ed1632ffbf63d883c64e.jpe done in 0:01:04.814513: "document_class": undetected, "face": {'size': {'width': 640, 'height': 480}, 'bounds': [{'top': 306, 'right': 381, 'bottom': 476, 'left': 211}], 'vectors': '...'}, "extracted_text": "
В команде указан тип документа, сэмплы результата обработки лиц и извлечения текста, время затраченное на обработку.
Сервер Staffcop¶
Лог расположен по адресу /var/log/staffcop/content_processing.log.
Сообщение об ошибке [ERROR] content_processing:420 API error: [Errno28] No space left on device указывает, что серверу недостаточно RAM-диска. Ошибка возникает при работе с большими файлами или большом количестве ядер на сервере. Чтобы ее исправить, увеличьте размер дисковой памяти.
Для увеличения памяти добавьте в /etc/staffcop/cpservice-config строку:
RAMDISK_SIZE = '5G'
Примечание
Рекомендуемое значение для RAMDISK_SIZE можно рассчитать следующим образом: умножьте максимальный размер файла на обработку на количество ядер сервера. По умолчанию используется 500 MБ.