Cервер распознавания графических объектов¶
Описание и возможности¶
Сервер распознавания устанавливается на отдельную от сервера Staffcop Enterprise (виртуальную) машину. В состав сервера входит несколько движков, извлекающих данные и обнаруживающих графические сущности в документах.
Возможности сервера распознавания:
обнаружение изображений документов с печатями: скан-копии, скриншоты, фотографии документов с оттиском печати;
обнаружение изображений паспорта гражданина России: скан-копии, скриншоты, фотографии главной страницы;
распознавание лиц и создание оповещений по результатам распознавания;
распознавание больших объёмов текста, в том числе текста с любых изображений (скан-копии, скриншоты, фотографии) или из файлов-контейнеров (например, формата PDF или в ZIP);
работа с наиболее популярными форматами хранения изображений: png, jpeg, jpg, jpe, pdf.
Рекомендуемые системные требования¶
Операционная система: Ubuntu 18.04 и выше.
Процессор: Intel или AMD с поддержкой AVX инструкций. Количество потоков/ядер зависит от числа пользователей.
Объём оперативной памяти: от 8 ГБ.
Размер диска: до 100 ГБ.
Количество потоков/ядер и объёма оперативной памяти¶
Примечание
Включенная опции «Снимки экрана по смене фокуса окна» при выключенной «Делать скриншоты только при смене процесса» генерирует очень большое количество скриншотов.
Как правило, у пользователя генерируется от 1500 до 2000 скриншотов в день, в зависимости от его активности и количества мониторов. Одно ядро в день может обработать до 28800 скриншотов.
Расчёт производится для 300 ПК при включенном модуле «снимки экрана».
Таким образом, количество скриншотов в день:
2000 * 300 = 600 000 скриншотов
Итоговое количество скриншотов делим на количество изображений, обрабатываемых одним ядром:
600 000 / 28 800 ≈ 21 потоков/ядер
Расчёт объёма оперативной памяти
В среднем для обработки изображения требуется около 80 МБ на ядро. Для расчёта объёма оперативной памяти, умножим количество ядер/потоков на объём памяти для одного ядра и одного потока:
21*80 = 1680 МБ
Параллельно работают конвертеры изображений и сама операционная система сервера. В зависимости от получаемых данных они требуют от 1 до 4 ГБ RAM.
Таким образом, для оптимального функционирования системы под большой нагрузкой, используйте на сервере от 8 ГБ оперативной памяти.
Установка сервера¶
Для работы анализатора графических объектов установите дополнительные пакеты:
sudo apt update
sudo apt -y install software-properties-common python3.7 libpoppler-cpp0v5 poppler-utils libsm6 python3.7-venv tesseract-ocr
Добавьте репозиторий Staffcop в список репозиториев системы и установите сервер распознавания при помощи apt:
wget -O - http://distr.staffcop.su/stable5.0/staffcop.gpg | sudo apt-key add -
echo "deb http://distr.staffcop.su/stable5.0 stable5.0 non-free" | sudo tee /etc/apt/sources.list.d/staffcop.list
sudo apt update
sudo apt install staffcop-cpservice
Общий размер пакета около 850 МБ - при низкой скорости доступа в Интернет скачивание может занять длительное время.
На этом установка программного обеспечения завершена.
Настройка на стороне сервера StaffCop Enterprise¶
Перед настройкой модуля «Анализ контента», включите доступ к API сервера в параметрах сервера StaffCop Enterprise:
зайдите в раздел «Панель управления → Параметры сервера» в веб-интерфейсе
выберите «Доступ к API разрешён»;
на открывшейся странице установите значение и нажмите «Сохранить».
Значение параметра «Доступ к API разрешён» изменится на «Да».
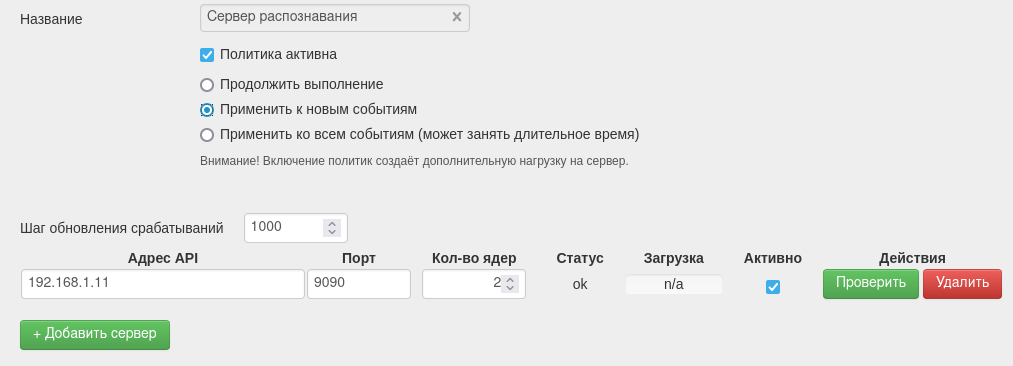
После этого в разделе Фильтры переключитесь на вкладку Политики и откройте окно настроек сервера распознавания: Системные политики / Сервер распознавания. Здесь расположены основные настройки сервера:
Шаг обновления срабатываний. Частота обновления распознанных изображений в веб-интерфейсе - чем меньше число, тем чаще будет происходить обновление. Оптимальное значение параметра - 10 000 - выставлено по умолчанию. Уменьшение этого значения сильно повысит нагрузку на сервер.
Адрес API. Доменное имя или IP-адрес сервера распознавания.
Порт. Порт доступа к серверу распознавания. По умолчанию - 9090.
Кол-во ядер. Должно соответствовать числу ядер сервера модуля.
Статус. Наличие связи с сервером.
Загрузка. Нагрузка на сервер распознавания.
Активно. Включение/выключение сервера распознавания.
Чтобы запустить сервер, укажите данные машины, на которой установлен сервер распознавания и установите галочку «Политика активна».
Настройка модуля «Анализ контент໶
Подключитесь к серверу распознавания по SSH. Откройте конфигурационный файл сервера в текстовом редакторе:
sudo nano –c /etc/staffcop/cpservice-config
И укажите следующие параметры:
PORT = 9090
SERVER_ADDR = 'http://192.168.1.x'
SECRET = 'xxxxxxxxxxxxxxxx'
Здесь PORT - порт доступа к серверу; SERVER_ADDR - адрес сервера StaffCop Enterprise; SECRET – значение ключа API, указанное в «Параметрах сервера» (см.выше).
Сохраните сделанные изменения и перезапустите сервер командой:
sudo service staffcop-cpservice restart
Готово! Сервер настроен.
Политики обработки контента¶
Настраиваются на сервере Staffcop в веб-интерфейсе.
Время на обработку изображений:
Формат изображения |
Время на обработку, с |
full HD изображение без поворота |
5 |
4K изображение |
20 |
изображение печати, паспорта, картинки в формате JPEG |
4 - 6 |
распознавание лица |
5 - 60 |
Распознавание текста¶
В разделе Фильтры перейдите на вкладку Политики и далее Системные политики → Распознавание текста».
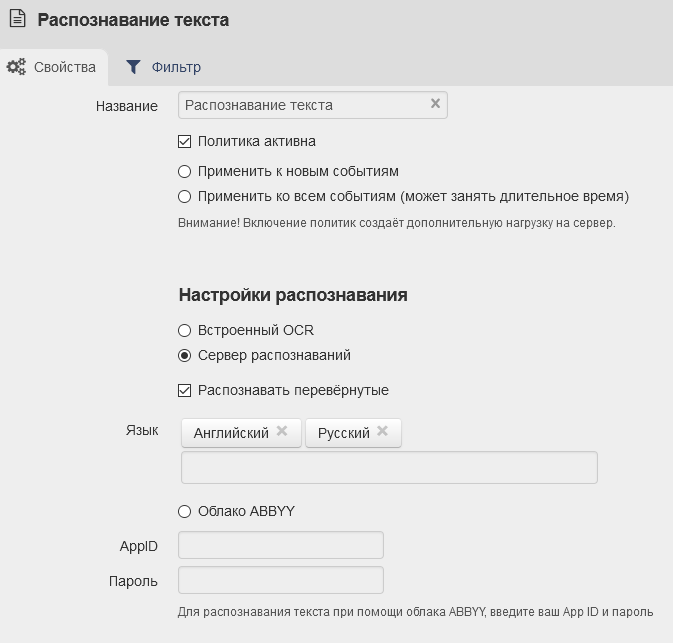
В открывшемся окне на вкладке Свойства доступны следующие опции:
Встроенный OCR / Сервер распознавания. Выбор инструмента распознавания для настраиваемых фильтров и политик.
Распознавать перевёрнутые. Распознавание текста на перевёрнутых изображениях. Расширяет возможности функции, но нагружает сервер распознавания.
Язык. Выбор языков, для которых производится распознавание текста.
Облако ABBYY. Возможность использования облачного сервиса ABBYY для распознавания текста на изображениях. Для подключения сервиса, укажите свой логин и праоль в системе.
На вкладке Фильтр можно настроить работу фильтра для политики распознавания текста. Настроенный по умолчанию фильтр выглядит так:
agent_attachedfile@mime:mime=application/pdf
agent_attachedfile@mime:mime=image/jpeg
agent_attachedfile@mime:mime=image/png
agent_attachedfile@mime:mime=image/tiff
agent_attachedfile@extracted:extracted=false
agent_eventtype@default:agent_eventtype=0#Intercepted file
{
"operator": "AND",
"rules": []
}
Распознавание печатей¶
Примечание
На данный момент поддерживается поиск только круглых печатей. Но при этом документ может содержать несколько разных печатей.
Сервер распознаваний находит в изображениях и документах формата jpg, jpe, jpeg, png и pdf изображения печати по заданным образцам.
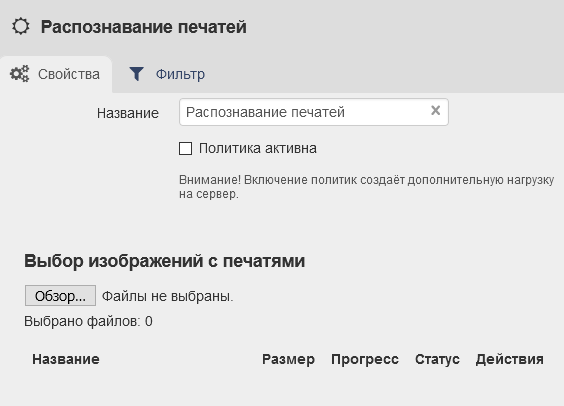
Чтобы создать политику распознавания печатей: Создать → Распознавание печатей.
Для работы политики понадобятся образцы печатей. Это могут быть фрагменты изображений, на котором содержится искомая печать. Окружающий текст и подписи не являются помехами для распознавания. Чтобы повысить качество распознавания используйте несколько образцов печати.
Что важно для таких образцов:
размер изображения - 400x400 px;
разная степень нажатия при печати;
небольшие различия между образцами;
отсутствие бракованных оттисков;
расположение печатей под разными углами.
После добавление образцов в политику, убедитесь, что модуль распознал печати на них - в столбце «Статус» для каждого образца появится галочка.
Задайте фильтр для политики. Например:
типы контента - pdf, jpg, png;
типы события - перехваченные файлы/скриншоты.
C пустым фильтром политика работать не будет. Для активации политики установите галочку «Политика активна». Найденные факты будет доступны в «Сработавшие политики».
Ложные срабатывания
Для любой политики распознавания образов существует вероятность ложного срабатывания. Чаще всего такое происходит с печатями, имеющими определённое сходство. Чтобы снизить количество ложных срабатываний, откройте конфигурационный файл сервера распознавания:
sudo nano /etc/config/staffcop/settings.py
и измените значения параметра STAMP_RECOGNITION_THRESHOLD в сторону уменьшения.
Ложные срабатывания возможны, когда компания или организация имеют похожие печати, отличающиеся названием отдела или кодом подразделения. В этом случае обратитесь в нашу техническую поддержку.
Поиск графических объектов¶
Позволяет распознавать несколько типов изображений:
паспорт РФ;
документы со штампами;
лица.
Паспорт РФ¶
Сервер распознаваний позволяет распознавать разворот главной страницы паспорта РФ в PDF-файлах, изображениях форматов png и jpeg, скриншотах.
Разворот главной страницы паспорта - страница с информацией о выдаче паспорта и страница с фотографией владельца.
Чтобы включить поиск паспорта РФ:
Создать → Поиск графических объектов → Паспорт РФ;
на вкладке Фильтр выберите критерии фильтра (тип события, тип контента и т.д.).
В результате в Сработавших политиках будут появляться события, подпадающие под установленные критерии.
Ложные срабатывания
В процессе работы могут появляться ложноположительные срабатывания, когда событие появилось в Сработавших политиках, но изображений с паспортом не содержит. Вероятность таких событий очень низка. Пожалуйста, передайте изображения, вызвавшие срабатывание, разработчикам. Если ложных срабатываний много, подключитесь к серверу распознавания и в файле /etc/staffcop/cpservice-config/settings.py добавьте строку PASSPORT_THRESHOLD :
PASSPORT_THRESHOLD = 0.7
Документы со штампами¶
Сервер распознавания может находить круглые печати и штампы в PDF-файлах, изоюбражениях формата png и jpeg и на скриншотах.
Для обнаружения печатей:
Создать → Поиск графических объектов → Документы со штампами;
на вкладке Фильтр выберите критерии фильтра (тип события, тип контента и т.п.).
В результате в Сработавшие политики начнут поступать солбытия, подпадающие под заданные критерии.
Ложные срабатывания
В процессе работы могут происходить ложноположительные срабатывания, когда событие появилось в Сработавших политиках, но печати не содержит. Если такие события происходят, пожалуйста, передайте изображения, на которых произошло срабатывание, в техническую поддержку. Чтобы понизить число ложных срабатываний, добавьте строку STAMP_THRESHOLD в файл /etc/staffcop/cpservice-config/settings.py на Сервере распознавания:
STAMP_THRESHOLD = 0.6
Примечание
Чем выше это значение, тем выше порог детектирования, тем меньше изображений будут попадать по срабатывание. При необходимости, можно поднять значение ещё выше. В этом случае, некоторые печати, в сомнительных и спорных ситуациях модель будет «пропускать».
Лица¶
Сервер распознавания содержит функцию распознавания лиц на снимках веб-камер. Результат распознавания фиксируется в виде соответствующего Алерта: «Нет лица», «Cвое лицо», «Неизвестное лицо», «Несколько лиц». Своё и Неизвестное лица определяются по заранее назначенным в веб-консоли снимкам их владельцев.
Для распознавания лиц при настроенном сервере распознавания и созданной политике:
Создать → Поиск графических объектов → Лица;
на вкладке Фильтр выберите критерии фильтра Снимки с веб-камер», тип контента - jpg, png.).
После поступления первых результатов распознаваний в веб-консоль,выберите снимок с подходящим освещением и ракурсом анфас (лицом к камере) в таблице событий. Нажмите на фотографию и в открывшемся диалоговом окне Распознавание лиц: Данное лицо принадлежит пользователю N?» ответьте Да, если лицо соответствует аккаунту. Эти действия нужно повторить один раз для каждого аккаунта.
Примечание
При ответе Нет ранее установленное соответствие будет сброшено! Используйте кнопку Закрыть, если случайн открыли это окно или решили ничего не менять.
Изменения в результате назначения лица будут применяться только к новым событиям. Проверьте, что лица на изображениях соответствуют владельцам компьютеров.
Алертs в Конструкторе для распознавания лиц:
Алерт |
Описание |
Нет лица |
Лица не обнаружены |
Своё лицо |
Обнаружено лицо. Это лицо владельца ПК. |
Неизвестное лицо |
Обнаружено лицо. Этого лица нет в базе. |
Несколько лиц |
На снимке присутствует несколько лиц. |
Нет снимка |
Снимок нечитаемый: темнота, отсутствие резкости… |
Ложные срабатывания
К ложным срабатываниям или полному отсутствию распознавания могут привести поворот головы, несоответствующий ракурс лица, закрытая, например рукой, часть лица. Повлиять на результат распознавания можно, уменьшив параметр FACE_DETECT_THRESHOLD в /etc/staffcop/config/settings.py:
FACE_DETECT_THRESHOLD = 0.5
Примечание
При необходимости параметр можно уменьшать до 0.4, но следует учитывать, что чем меньше значение, тем меньше распознаваний.
Распознавание на иных изображениях, кроме снимков веб-камер
Чтобы распознать лица не только на снимках веб-камер, в фильтре политики Распознавание лиц выберите подходящие критерии. В /etc/staffcop/config/settings.py добавьте запись:
FACES_TYPES = ( "WebcamSnapshot", "Screenshot", "InterceptedFile")
и перезапустите Staffcop:
sudo service staffcop restart
Логи работы сервера распознавания¶
На стороне сервера лог расположен здесь: /var/log/staffcop-cpservice.err
Запрос и его опции:
2020-09-10 12:19:39,065 [DEBUG] cp_server:112 Request for 2020_09_10/ae4cd000abaecdaf46eec3d3ac90750d327e688a.jpe : text_extraction face_detection
Здесь: text_extraction face_detection - опциональные параметры, извлечение текста и распознавание лиц.
Результат обработки:
2020-09-10 12:24:20,125 [DEBUG] cp_server:127 Response for 2020_09_10/9ade404783b02bff8741ed1632ffbf63d883c64e.jpe done in 0:01:04.814513: "document_class": undetected, "face": {'size': {'width': 640, 'height': 480}, 'bounds': [{'top': 306, 'right': 381, 'bottom': 476, 'left': 211}], 'vectors': '...'}, "extracted_text": "
Здесь указан тип документа, сэмплы результата обработки лиц и извлечения текста, время затраченное на обработку.
На стороне Staffcop лог расположен по адресу /var/log/staffcop/process.log.
Начало и конец запуска обработки серии событий:
2020-09-10 12:19:38,877 [INFO] graphic_objects_detector:152 Графические объекты: process range 53793 - 53840
...
2020-09-10 12:26:14,148 [INFO] graphic_objects_detector:212 Графические объекты: finished at 53840. Time: 0:06
Если в ходе работы появилась ошибка [ERROR] content_processing:420 API error: [Errno28] No space left on device, это значит, что серверу недостаточно RAM-диска. Это может произойти при работе с большими файлами или большом количестве ядер на сервере. Чтобы исправить ошибку, увеличьте размер дисковой памяти. Добавьте в /etc/staffcop/cpservice-config строку:
RAMDISK_SIZE = '5G'
Примечание
Рекомендуемое значение RAMDISK_SIZE: максимальный размер файла на обработку умножить на число ядер. По-умолчанию используется 500M.
Дополнительные особенности функции распознавания лиц:
Присутствует проверка на «заглушенные камеры» - заклеенные камеры, сбитая резкость и т.д. В срабатывания так же могут попадать трудно различимые для компьютерного зрения изображения, темнота и подобное. Если в алерте «Нет снимка» часто происходят нежелательные срабатывания, обратитесь в техническую поддержку.
Площадь лица для корректного распознавания, должна составлять не менее 2,5% от площади изображения.
При распознавании нескольких лиц их размеры не должны отличаться друг от друга более, чем в два раза. Это исключит срабатывание на случайно попавшие в поле зрения камеры лица вдалеке.
Лица не должны пересекаться. Центр меньшего лица не должен лежать внутри рамки большего, в противном случае, меньшее лицо игнорируется.
Одно и то же лицо, имеющееся в базе, не может распознаться на изображении более одного раза. Избыточные срабатывания игнорируются.
Алгоритм распознавания лиц - HOG.