Установка сервера распознавания графических объектов¶
Описание и возможности модуля¶
Модуль представляет из себя программный пакет, устанавливаемый на отдельно стоящий сервер (виртуальную машину) в дополнение к серверу Staffcop Enterprise (т.е. отдельный от Staffcop сервер). Cодержит в себе несколько движков, извлекающих данные либо обнаруживающих различные графические и иные сущности из документов.
В данный момент доступны следующие возможности:
обнаружение изображений документов с печатями: скан-копии, скриншоты, фотографии, где есть документы с оттиском печати;
обнаружение изображений паспорта гражданина России: скан-копии, скриншоты, фотографии с главной страницей паспорта гражданина России;
распознавание лиц и создание оповещений по результатам распознавания;
эффективное распознавание больших объёмов текста с использованием технологии многопоточного распознавания, пригодной для обработки большого потока документов. Возможно распознавание текстов в любых изображениях, на которых имеется текст: скан-копии, скриншоты, фотографии, а также в файлах-контейнерах (например, файлах формата PDF или в ZIP-архивах).
Рекомендуемые требования к серверу распознаваний¶
Операционная система: Ubuntu 18.04
Процессор: Intel или AMD с подержкой AVX инструкций.
Память: от 2 ГБ на ядро.
Размер диска: от 20 ГБ до 50 ГБ.
Детектирование печати, паспорта или картинки через CR Tesseract 4 в формате JPG в размере FullHD займет 4-6 секунд.
Детектирование лица занимает от 5 и до 60-ти секунд.
1 ядро, мин. |
2 ядра, мин. |
3 ядра, мин. |
4 ядра, мин. |
Изоб. FullHD/сек |
Кол-во изображений |
Множитель ядер |
|---|---|---|---|---|---|---|
83.3 |
41.7 |
20.8 |
10.4 |
5 |
1000 |
1 |
166.7 |
83.3 |
41.7 |
20.8 |
5 |
2000 |
2 |
416.7 |
208.3 |
104.2 |
52.1 |
5 |
5000 |
4 |
833.3 |
666.7 |
208.3 |
104.2 |
5 |
10000 |
8 |
Установка модуля на сервер¶
Для работы анализатора графических объектов Staffcop требуется установить дополнительные пакеты:
sudo apt update
sudo apt -y install software-properties-common python3.7 libpoppler-cpp0v5 poppler-utils libsm6 python3.7-venv tesseract-ocr
Прописываем репозиторий Staffcop и ставим модуль при помощи apt:
wget -O - http://distr.staffcop.su/stable4.8/staffcop.gpg | sudo apt-key add -
echo "deb http://distr.staffcop.su/stable4.8 stable4.8 non-free" | sudo tee /etc/apt/sources.list.d/staffcop.list
sudo apt update
Теперь устанавливаем пакет модуля сервера разпознований:
sudo apt install staffcop-cpservice
Примечание
Размер пакета около 800 MB, поэтому в случае низкой скорости доступа в сеть Интернет скачивание может занять значительное время.
На этом установка программного обеспечения завершена.
Настройка со стороны сервера StaffCop Enterprise¶
Прежде чем настраивать модуль «Анализ контента», нужно в параметрах сервера StaffCop Enterprise включить доступ к API сервера, так как по умолчанию этот доступ выключен.
Для этого нужно открыть страницу параметров сервера в web-интерфейсе (пункт меню «Панель управления -> Параметры сервера»):
и на открывшейся странице параметров сервера кликнуть по параметру «Доступ к API разрешён»:
Откроется страница изменения параметра, нужно на ней установить значение и нажать кнопку «Сохранить». Значение против параметра «Доступ к API разрешён» изменится на «Да»
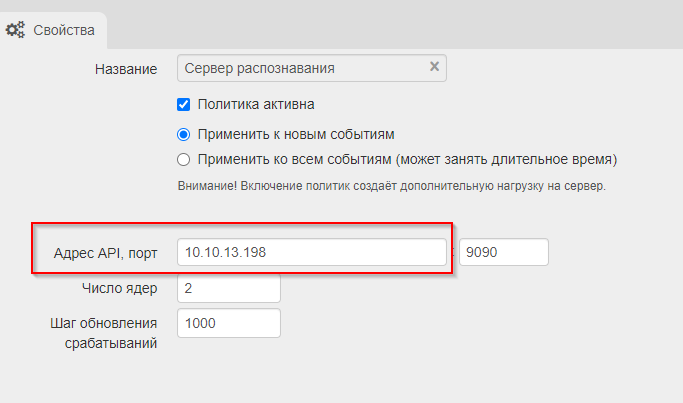
Дальше открываем вкалдку Фильтры, а в ней «Политики -> Системные политики -> Сервер распознаваний», где расположены следующие параметры:
Адрес API виде http://cpservice.atom.local : 9090, где cpservice.atom.local - доменное имя или IP сервера с модулем, 9090 - рабочий порт, указанный при установке модуля.
Число ядер должно соответствовать числу ядер сервера модуля.
Шаг обновления срабатываний - чем меньше (минимально рекомендуемое значение 100), тем чаще распознанные данные будут отображаться в интерфейсе, сработавших политиках, но тем чаще обработка политики будет посылать тяжёлые запросы к БД. В нормальном режиме работы рекомендуется число от 1000-10000.
Для запуска работы установить галочку «Политика активна».
Настройки модуля «Анализ контента» на сервере распознавания изображений¶
Нужно открыть SSH-консоль сервера распознавания изображений одним из распространённых приложений, например PuTTY.
Настройка модуля «Анализ контента» выполняется изменением текстовых конфигурационных файлов модуля с помощью редактора текстов nano.
Запускается редактор nano с именем редактируемого файла конфигурации sudo nano –c /etc/staffcop/cpservice-config
PORT = 9090
SERVER_ADDR = 'http://192.168.1.x'
SECRET = 'xxxxxxxxxxxxxxxx'
Нужно изменить значение параметра SERVER_ADDR на адрес вашего сервера StaffCop Enterprise, а значение параметра SECRET – на значение ключа API, которое берётся из «Параметров сервера» (см.выше):
После изменения параметров нужно выйти из редактирования нажатием Ctrl-X, подтвердив запись файла нажатием Y и Enter.
Все параметры конфигурации сервиса распознавания изображений заданы, теперь его нужно перезапустить командой
sudo service staffcop-cpservice restart
Настройка модуля завершена.
Политики для обработки контента¶
Настраиваются на сервере Staffcop в веб-интерфейсе.
Распознавание текста¶
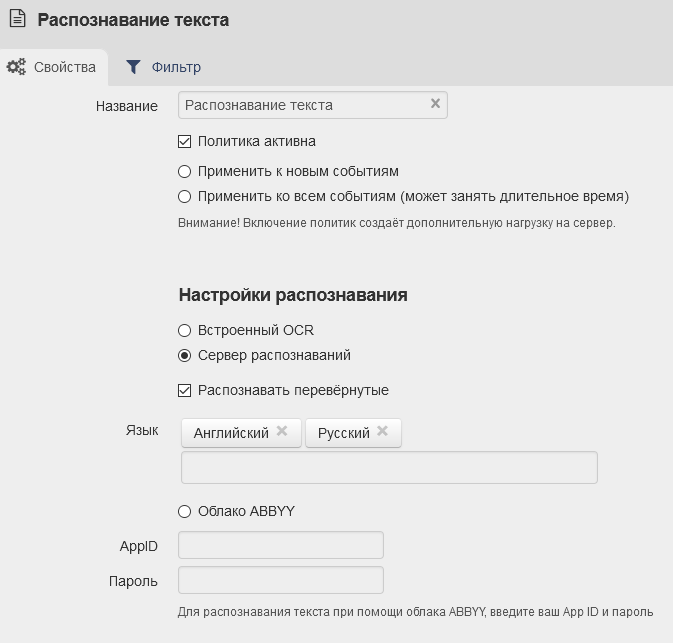
Данная политика расположена в Фильтрах. Выбираем пункт «Политики -> Системные политики -> Распознавание текста».
В настройках распознавания необходимо выбрать пункт «Сервер распознаваний». После сохранить изменения.
Распознавание печатей¶
«Сервер распознаваний» способен находить в изображениях и документах (jpg, png, pdf) печать по заданным образцам. Поддерживаются только круглые печати, при этом документ может содержать несколько разных печатей.
Данная политика создается через пункт меню в верхнем левом углу «Создать -> Распознование печатей»
Понадобятся образцы - фрагменты изображения, содержащего искомую печать. Окружающий тест, подписи так же не являются значительной помехой. Лучше, если образцов будет несколько (от 3 до 10) — это повысит качество распознавания. Подходящим размером такого образца может быть 400x400px.
Примечание
Выбирая несколько образцов, лучше, если они будут отличаться углом наклона, неравномерностью нажатия и иметь небольшие отличия, но без явного брака. Образец не должен содержать фрагменты иных печатей.
Политика служит для нахождения документов с оттиском конкретной печати. При создании политики, нужно выбрать образец или несколько разных оттисков одной печати, каждый образец - изображение (jpg или png) c одной печатью на нём.
Добавить выбранные образцы в политику, убедиться, что модуль распознал печати на них - в столбце «Статус» для каждого образца должна появится галочка.
Так же, установить фильтр для политики: например, типы контента pdf, jpg, png, типы события - перехваченные файлы/скриншоты. C пустым фильтром политика работать не будет. Для активации политики установить галочку «Политика активна». Найденные факты будет доступны в «Сработавших фильтрах».
Ложные срабатывания
Чаще всего такое происходит с печатями, имеющими определённое сходство. Ситуацию можно исправить, изменив параметр STAMP_RECOGNITION_THRESHOLD в сторону уменьшения. Например, если в settings.py значение STAMP_RECOGNITION_THRESHOLD = 0.6, попробовать сменить на 0.5 или ниже в /etc/config/staffcop.
STAMP_RECOGNITION_THRESHOLD = 0.5
Примечание
Ложно положительные срабатывания возможны, когда компания или организация имеют действительно похожие печати, отличающиеся лишь в названии отдела, либо кода подразделения. В этом случае, необходимо обратиться за помощью в техническую поддержку.
Поиск графических объектов¶
Данная политика было вынесена отдельна, так как имеет несколько типов обратки информации (Паспорт РФ, Документы со штампами, Лица). Ниже мы рассмотрем каждый из них.
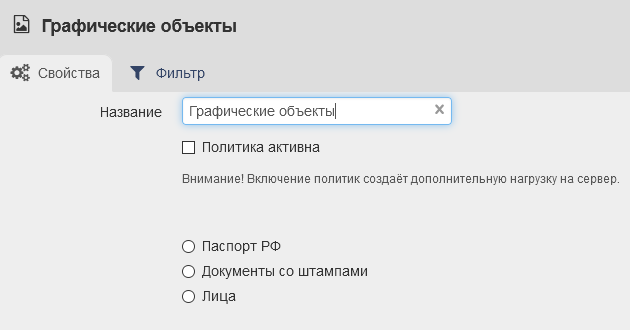
Паспорт РФ¶
Модуль «Сервер распознаваний» имеет функционал обнаружения разворотов главной страницы паспортов РФ (страницы, содержащей информацию о выдаче + страницы с фотографией владельца) в PDF-файлах и изображениях (png, jpeg, в т.ч. скриншотах).
Для активации функционала, необходимо создать политику «Поиск графических объектов → Паспорт РФ». Во вкладке «Фильтр» выбрать критерии фильтра (обычно типа события, тип контента и т.п.).
Результатом работы политики станет появление помеченных событий в «Сработавших фильтрах» по названию созданной выше политики типа «Поиск графических объектов» по мере поступления событий, подпадающих под критерий фильтра политики и содержащих печать.
Ложные срабатывания
В процессе работы политики могут случиться ложноположительные срабатывания, когда событие появилось в «Сработавших фильтрах» по названию политики, но паспортов не содержит. Вероятность подобного оценивается как низкое, тем не менее, при наличии возможности, следует передать подобные изображения разработчикам. Скорое всего, это будут изображения подобных документов. Если таких срабатываний будет много, следует увеличить параметр PASSPORT_THRESHOLD, добавив строчку в /etc/staffcop/cpservice-config на «Сервере распознаваний»:
PASSPORT_THRESHOLD = 0.7
Документы со штампами¶
Модуль «Сервер распознаваний» имеет функционал обнаружения круглых печатей (штампов) в PDF-файлах и изображениях (png, jpeg, в т.ч. скриншотах).
Для детектирования печатей, необходимо создать политику «Поиск графических объектов → Документы со штампами». Во вкладке «Фильтр» выбрать критерии фильтра (обычно типа события, тип контента и т.п.).
Результатом работы политики станет появление помеченных событий в «Сработавших фильтрах» по названию созданной выше политики типа «Поиск графических объектов» по мере поступления событий, подпадающих под критерий фильтра политики и содержащих печать.
Ложные срабатывания
В процессе работы политики могут случиться ложноположительные срабатывания, когда событие появилось в «Сработавших фильтрах» по названию политики, но печати не содержит. Вместо этого на изображении может быть что-то круглое, например аватар или какой-то логитип, который модель ошибочно посчитала печатью. Обычно, подобное просиходит, если под фильтр попадают скриншоты. Если такие срабатывания происходят достаточно редко - желательно собирать их и передавать в техническую поддержку. Если достаточно часто - нужно увеличить параметр STAMP_THRESHOLD, добавив строчку в /etc/staffcop/cpservice-config на «Сервере распознаваний»:
STAMP_THRESHOLD = 0.6
Примечание
Чем выше это значение, тем выше порог детектирования, тем меньше изображений будут попадать по срабатывание. При необходимости, можно поднять значение ещё выше. В этом случае, некоторые печати, в сомнительных и спорных ситуациях модель будет «пропускать».
Лица¶
«Сервер распознаваний» содержит функцию распознавания лиц на снимках веб-камер. Результат распознавания фиксируется в виде соответствующего Алерта: Нет лица, Cвое лицо, Неизвестное лицо, Несколько лиц. Своё/Неизвестное лица детектируются благодаря заранее назначенным в веб-консоле снимкам для их владельцев.
Необходимо создать политику «Поиск графических объектов → Лица». Во вкладке «Фильтр» выбрать критерии фильтра (обычно типа события «Снимки с веб-камер», тип контента - jpg, png.). Предоплагается наличие уже настроенного и работающего «Сервера распознаваний» и одноимённой политики.
После поступления первых результатов распознаваний в веб-консоль следует выбрать снимок с подходящим освещением и ракурсом анфас (лицом к камере) в таблице событий. Нужно кликнуть указателем курсора внутрь рамки вокруг лица, отчего откроется диалог «Распознавание лиц: Данное лицо принадлежит пользователю N?», и ответить «Да», если лицо соответствует аккаунту. Данную процедуру нужно проделать один раз для каждого аккаунта.
Примечание
Если ответить нет, то ранее установленное соответствие будет сброшено! Пользуйтеся кнопкой «Закрыть» если окно открыто случайно, или вы передумали что-то менять.
Изменения в результате назначения лица будут применяться только к новым событиями. Проследите за тем, что новые снимки корректно ассициируются с лицами, на них изображённых.
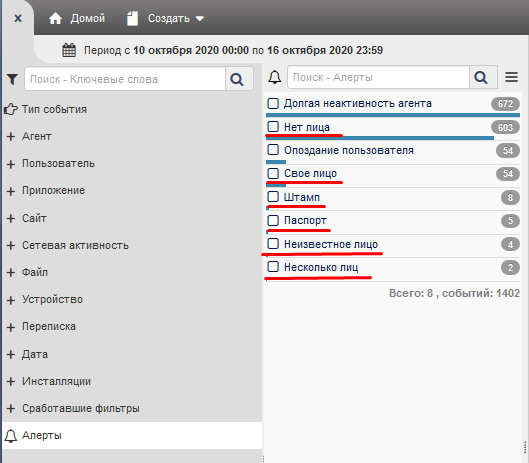
Результаты можно увидеть в «Конструкторе» веб-консоли в виде Алертов:
Нет лица: лица на снимке не обнаружены.
Cвое лицо: обнаружено лицо и идентифицировано как пользователь в данный момент работающий за ПК.
Неизвестное лицо: обнаружено лицо, но не идентифицировано, т.е. не совпадает ни с одним из имеющихся в базе лиц.
Посторонее лицо: лицо, соответствующее с одним из имеющихся в базе, но не являющееся пользователем ПК в данный момент.
Несколько лиц: на снимке присутствует несколько лиц, независимо от их принадлежности.
Нет снимка: снимок не читаемый, темнота, отсутствие резкости.
Ложные срабатывания
Следует учитывать, что поворот головы, несоответствующий ракурс лица, заслонённая часть лица рукой приведут к отсутствию распознавания. Так же, в некоторых случаях, возможно неверное соответствие лица. Повлиять на результат можно, уменьшив параметр FACE_DETECT_THRESHOLD, добавив в /etc/staffcop/config строчку:
FACE_DETECT_THRESHOLD = 0.5
Примечание
При необходимости параметр можно уменьшать ещё, до 0.4, но следует учитывать - чем меньше значение, тем меньше распознаваний вообще.
Распознавание на иных изображениях, кроме снимков веб-камер
Изначально функционал был создан для работы с веб-камерами, однако, можно работать и с другими изображениями и перехваченными файлами. Для этого в фильтре политики «Распознавания лиц» выбрать подхоящие критерии. В /etc/staffcop/config добавить запись:
FACES_TYPES = ( "WebcamSnapshot", "Screenshot", "InterceptedFile")
После чего рестаровать Staffcop:
sudo service staffcop restart
Мониторинг работы модуля распознавания изображений в логах¶
На стороне модуля смотреть лог /var/log/staffcop-cpservice.err
Запрос и его опции:
2020-09-10 12:19:39,065 [DEBUG] cp_server:112 Request for 2020_09_10/ae4cd000abaecdaf46eec3d3ac90750d327e688a.jpe : text_extraction face_detection
Здесь: text_extraction face_detection - опциональные параметры, извлечение текста и распознавание лиц.
Результат обработки:
2020-09-10 12:24:20,125 [DEBUG] cp_server:127 Response for 2020_09_10/9ade404783b02bff8741ed1632ffbf63d883c64e.jpe done in 0:01:04.814513: "document_class": undetected, "face": {'size': {'width': 640, 'height': 480}, 'bounds': [{'top': 306, 'right': 381, 'bottom': 476, 'left': 211}], 'vectors': '...'}, "extracted_text": "
Здесь указан тип документа, сэмплы результат обработки лиц и извлечения текста, время затраченное на обработку.
На стороне Staffcop лог /var/log/staffcop/process.log, начало и конец запуска обработки серии событий:
2020-09-10 12:19:38,877 [INFO] graphic_objects_detector:152 Графические объекты: process range 53793 - 53840
...
2020-09-10 12:26:14,148 [INFO] graphic_objects_detector:212 Графические объекты: finished at 53840. Time: 0:06
Дополнение для распознавания лиц¶
По результатам внутреннего тестирования выполнены следующие доработки влияющие на результаты:
Добавлена проверка на «заглушенные камеры» - заклееные, сбитая резкость и прочее. В срабатывания так же могут попадать трудно различимые для компьютерного зрения изображения, темнота и подобное. Если в «Нет снимка» часто происходят нежелательные срабатывания, потребуется помощь разработчика.
Для распознавания лиц требуется, чтобы площадь лица составляла не менее 2.5% от площади изображения (лица вдалеке определяться не должны).
При распознавании нескольких лиц они не должны отличаться друг от друга более, чем в два раза, чтобы исключить срабатывание на случайно оказавшихся вдалеке в поле зрения камеры. Лица, меньшие, чем в два раза, игнорируются.
Лица не должны пересекаться. Центр меньшего лица не должен лежать внутри рамки большего, в противном случае, такое лицо игнорируется.
Одно и то же лицо, имеющееся в базе назначенных для аккаунтов, не может распознаться на изображении более одного раза. Избыточые срабатывания игнорируются.
Алгоритм детектирования лиц переключен на более быстрый и производительный HOG. Ранее мы тестировали с алгоритмом CNN.