Установка сервера распознавания графических объектов¶
Описание и возможности модуля¶
Модуль «Анализ контента» представляет собой дополнительный модуль для программного комплекса мониторинга StaffCop Enterprise. В стандартный комплект поставки модуль не входит, но он может быть установлен отдельно как дополнительный программный пакет. Загрузка и дальнейшее использование модуля бесплатны, как и консультации технической поддержки StaffCop по его установке. Модуль совместим с любым релизом StaffCop Enterprise, начиная с версии 4.7, и работает на версии ОС Ubuntu 18.04.4 LTS.
Поскольку модуль анализа контента достаточно сильно нагружает сервер (в основном вычислительные мощности – ядра процессора), настоятельно рекомендуется устанавливать его на ОТДЕЛЬНЫЙ сервер. При установке модуля на тот же сервер, на котором работает основной комплекс StaffCop Enterprise, стабильная работа не гарантируется, так как возможна перегрузка процессора. Модуль включает в себя несколько перспективных технологий, извлекающих или обнаруживающих определённые графические объекты в документах, а именно:
обнаружение изображений документов с печатями: скан-копии, скриншоты, фотографии, где есть документы с оттиском печати;
обнаружение изображений паспорта гражданина России: скан-копии, скриншоты, фотографии с главной страницей паспорта гражданина России;
распознавание лиц и создание оповещений по результатам распознавания;
эффективное распознавание больших объёмов текста с использованием технологии многопоточного распознавания, пригодной для обработки большого потока документов. Возможно распознавание текстов в любых изображениях, на которых имеется текст: скан-копии, скриншоты, фотографии, а также в файлах-контейнерах (например, файлах формата PDF или в ZIP-архивах).
Рекомендуемые требования к серверу распознаваний¶
Процессор: Из семейства Intel.
Память: от 2 ГБ на ядро.
Размер диска: зависит от количества изображений обрабатываемых в месяц.
Детектирование печати, паспорта или картинки через CR Tesseract 4 в формате JPG в размере FullHD займет 4-6 секунд.
Детектирование лица занимает от 5 и до 60-ти секунд.
1 ядро, мин. |
2 ядра, мин. |
3 ядра, мин. |
4 ядра, мин. |
Изоб. FullHD/сек |
Кол-во изображений |
Множитель ядер |
|---|---|---|---|---|---|---|
83.3 |
41.7 |
20.8 |
10.4 |
5 |
1000 |
1 |
166.7 |
83.3 |
41.7 |
20.8 |
5 |
2000 |
2 |
416.7 |
208.3 |
104.2 |
52.1 |
5 |
5000 |
4 |
833.3 |
666.7 |
208.3 |
104.2 |
5 |
10000 |
8 |
Установка модуля на сервер¶
Установка модуля «Анализ контента» производится на «чистый» сервер Ubuntu 18.04.4 LTS с фиксированным статическим адресом. Предполагается, что установка и настройка «чистого» сервера уже выполнены, адрес сервера распознавания изображений – 192.168.124.104, адрес сервера StaffCop Enterprise – 192.168.124.46.
Для установки модуля «Анализ контента» нужно, чтобы сервер распознавания изображений обязательно имел доступ в сеть Интернет: это необходимо для скачивания вспомогательных пакетов, зависимостей и самого пакета дополнительного модуля.
Сразу после установки модуля политика поиска и распознавания графических объектов будет активирована, и будет выполняться анализ всех новых событий, поступающих от агентов. Начиная с версии 4.7.1022 эта политика является стандартной, т.е. включена в поставку «из коробки».
Установка программного обеспечения может быть выполнена только от имени суперпользователя (пользователя root), поэтому после входа в консоль сервера нужно перейти в режим суперпользователя командой
sudo su –
Будет запрошен пароль текущего пользователя, после ввода пароля появится приглашение работы в режиме суперпользователя.
Сначала нужно скачать и установить дополнительные пакеты, необходимые для работы модуля «Анализ контента», командой:
sudo apt update
sudo apt -y install software-properties-common python3.7 libpoppler-cpp0v5 poppler-utils libsm6 python3.7-venv tesseract-ocr
Она извлечёт дополнительные зависимости пакетов, после чего выдаст запрос на подтверждение скачивания и установки запрошенных пакетов.
После подтверждения будут установлены и настроены запрошенные пакеты и их зависимости:
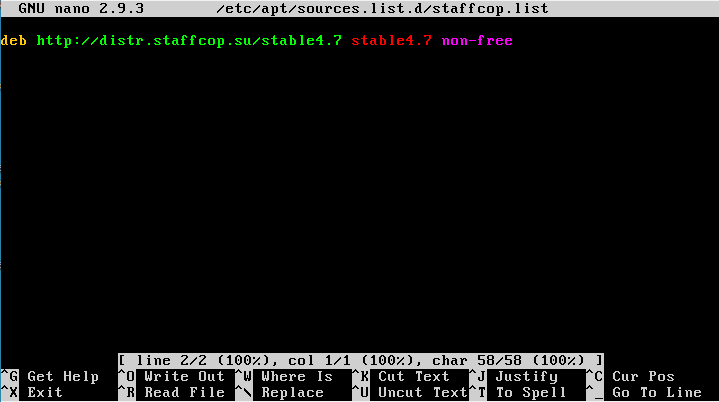
Далее, нужно добавить в репозиторий сервера распознавания изображений репозиторий StaffCop Enterprise, чтобы в будущем можно было обновлять пакет распознавателя изображений. Для этого с помощью редактора nano нужно в папке /etc/apt/sources.list.d/ создать файл staffcop.list, добавив в него одну строку
deb http://distr.staffcop.su/stable4.7 stable4.7 non-free
после чего подключить этот репозиторий командой
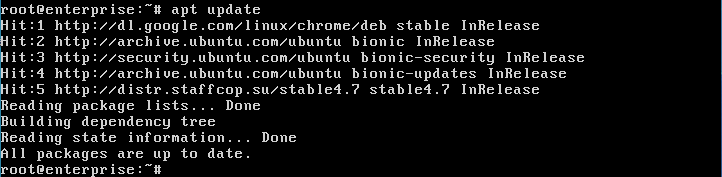
apt update
и убедиться, что он подключён без ошибок:
Вспомогательные пакеты установлены и настроены.
Скачиваем пакет модуля с сайта http://distr.staffcop.su/stable4.7/pool/non-free/s/staffcop-cpservice/ командой:
wget http://distr.staffcop.su/beta4.8/pool/non-free/s/staffcop-cpservice/staffcop-cpservice-0.5.2-master.deb && sudo dpkg -i staffcop-cpservice-0.4.3-master.deb
Пакет модуля будет установлен.
Примечание
Размер пакета – 550 MB, поэтому в случае низкой скорости доступа в сеть Интернет скачивание может занять значительное время.
После этого можно запросить обновления пакета набором команд
apt update && apt -y upgrade
Если обновлённый пакет существует, его надо установить.
Установка программного обеспечения завершена.
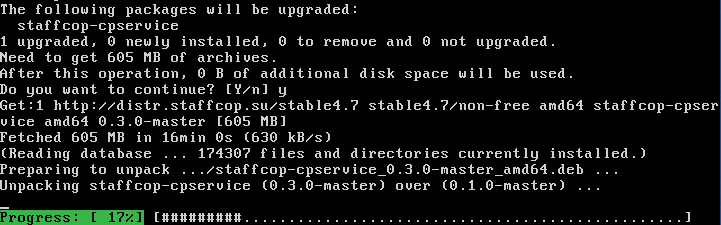
Настройка взаимодействия серверов «Анализа контента» и сервера StaffCop Enterprise¶
Прежде чем настраивать модуль «Анализ контента», нужно в параметрах сервера StaffCop Enterprise включить доступ к API сервера.
По умолчанию этот доступ выключен.
Для этого нужно открыть страницу параметров сервера (пункт меню «Панель управления -> Параметры сервера»:
и на открывшейся странице параметров сервера кликнуть по параметру «Доступ к API разрешён»:
Откроется страница изменения параметра, нужно на ней установить значение и нажать кнопку «Сохранить». Значение против параметра «Доступ к API разрешён» изменится на «Да»

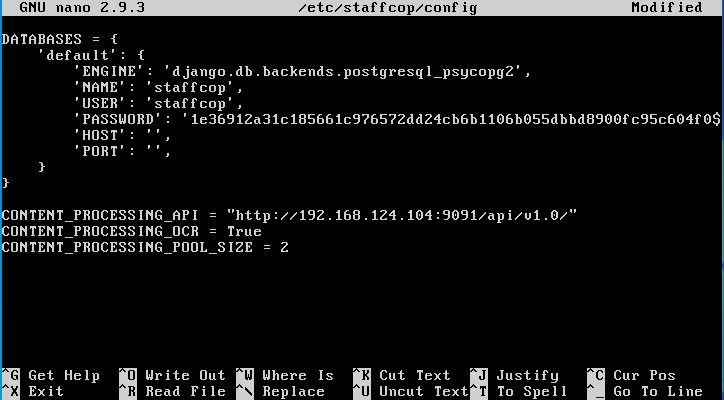
Далее, в файле /etc/staffcop/config на сервере StaffCop Enterprise нужно добавить строки параметров синхронизации для сервера распознавания изображений:
CONTENT_PROCESSING_API = "http://ai.atom.local:9090/api/v1.0/"
CONTENT_PROCESSING_POOL_SIZE = 2
CP_POLICY_BATCH = 100
где адрес сервера нужно заменить на ваш адрес сервера распознавания изображений.
Делается это с помощью того же редактора nano командой
nano /etc/staffcop/config
В окне редактора нужно добавить эти строки в конец файла:
После изменения параметров нужно выйти из редактирования нажатием Ctrl-X, подтвердив запись файла нажатием Y и Enter.
Настройки модуля «Анализ контента» на сервере распознавания изображений¶
Нужно открыть SSH-консоль сервера распознавания изображений одним из распространённых приложений, например PuTTY.
Настройка модуля «Анализ контента» выполняется изменением текстовых конфигурационных файлов модуля с помощью редактора текстов nano.
Запускается редактор nano с именем редактируемого файла конфигурации nano –c /usr/share/staffcop-cpservice/staffcop_worker/conf.py
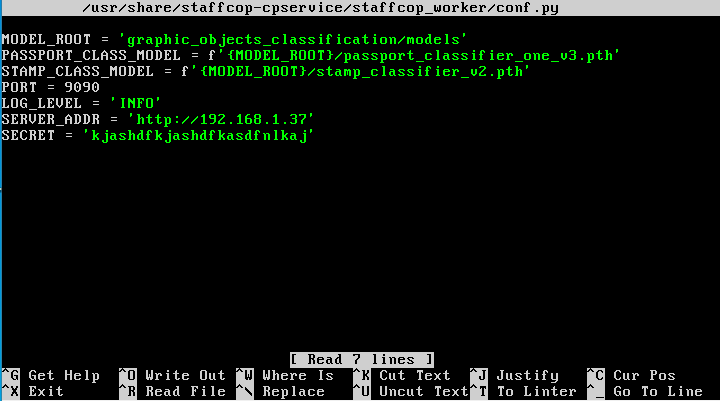
Нужно изменить значение параметра SERVER_ADDR на адрес вашего сервера StaffCop Enterprise, а значение параметра SECRET – на значение ключа API, которое берётся из «Параметров сервера» (см.выше):
После изменения параметров нужно выйти из редактирования нажатием Ctrl-X, подтвердив запись файла нажатием Y и Enter.
Все параметры конфигурации сервиса распознавания изображений заданы, теперь его нужно перезапустить командой
service staffcop-cpservice restart
Убедиться, что сервис стартовал можно заглянув в файл sudo tail -f /var/log/staffcop-cpservice.err:
2020-09-10 12:19:12,424 [DEBUG] selector_events:58 Using selector: EpollSelector
Настройка модуля завершена.
Включение политики «графичские объекты» в веб-интерфейсе Staffcop¶
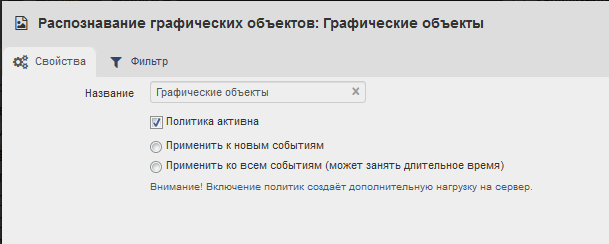
В веб-консоли Staffcop Enterprise на вкладке Фильтры выбрать политику Политики - Системные политики - Графические объекты.
Включить подходящий фильтр (по умолчанию - png, jpg, pdf -файлы), активировать галочку «Политика активна».
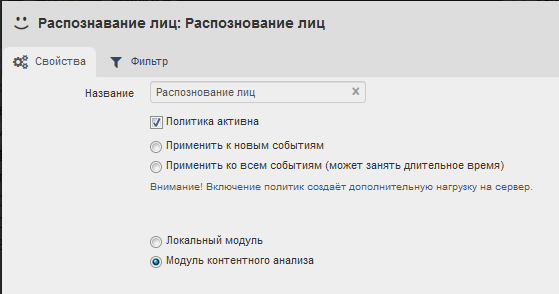
Для активации распознавания лиц лиц в дополнение к «Графическим объектам», нужно в политике «Распознавание лиц» выбрать галочку «Модуль контентного анализа» и «Политика активна».
Распознавание текста активируется аналогично в одноимённой политике чекбоксом «Модуль контентного анализа».
Срабатывание политики распознавания графических изображений¶
Как уже говорилось выше, политика распознавания изображений запустится сразу же после её активации.
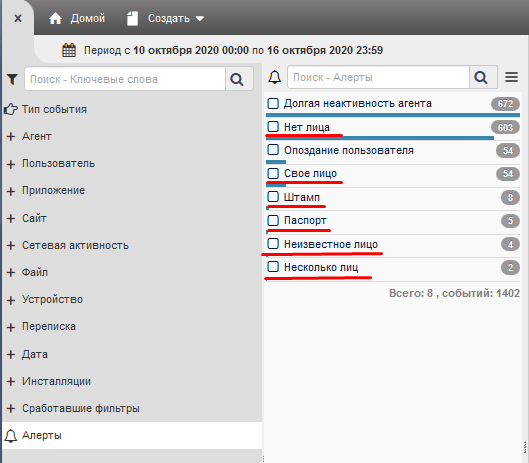
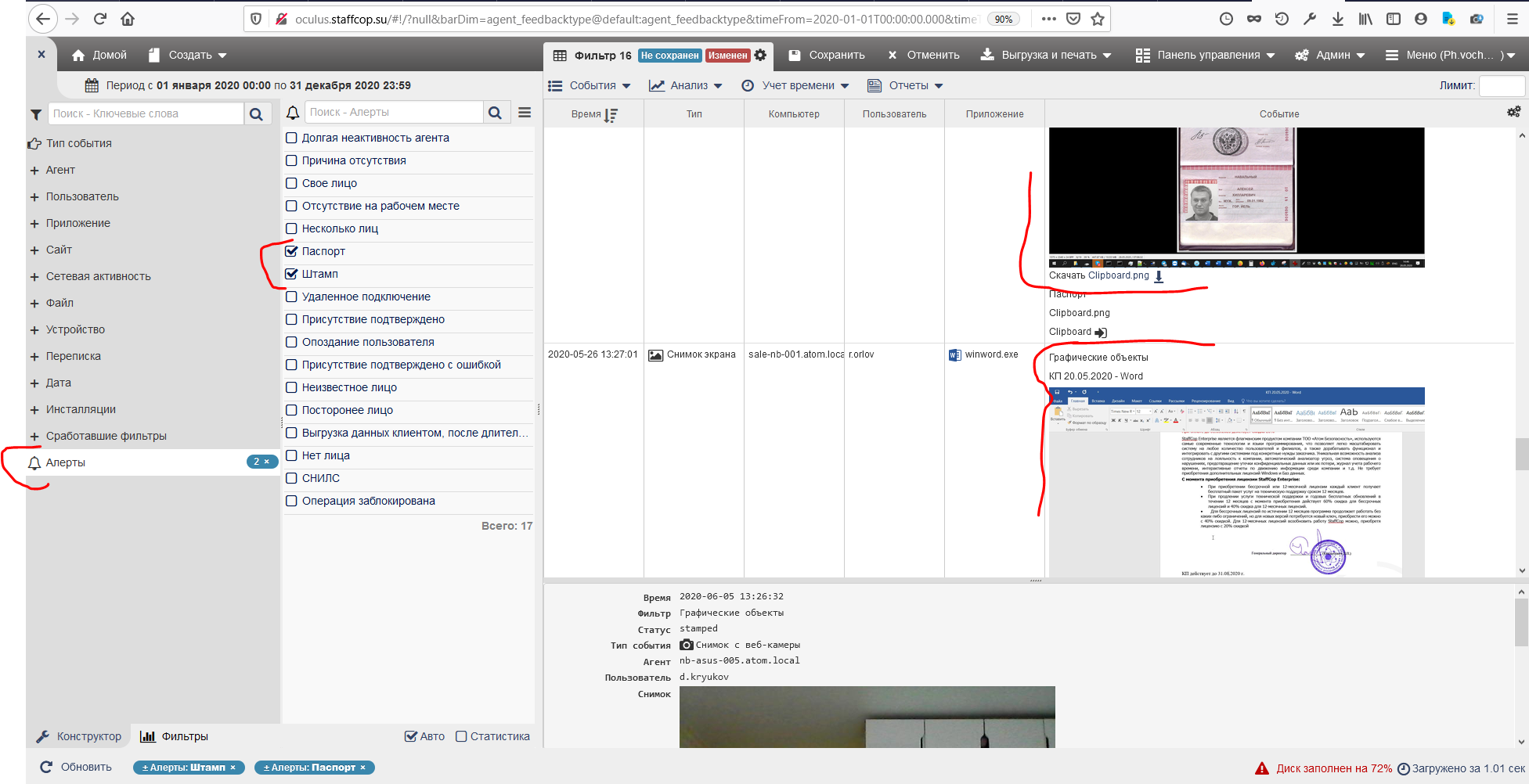
Если в перехваченных событиях были изображения, содержащие паспорта или печати, то в папке Алерты Конструктора будут отображены события Паспорт или Штамп:
Мониторинг работы модуля распознавания изображений в логах¶
На стороне модуля смотреть лог /var/log/staffcop-cpservice.err
Запрос и его опции:
2020-09-10 12:19:39,065 [DEBUG] cp_server:112 Request for 2020_09_10/ae4cd000abaecdaf46eec3d3ac90750d327e688a.jpe : text_extraction face_detection
Здесь: text_extraction face_detection - опциональные параметры, извлечение текста и распознавание лиц.
Результат обработки:
2020-09-10 12:24:20,125 [DEBUG] cp_server:127 Response for 2020_09_10/9ade404783b02bff8741ed1632ffbf63d883c64e.jpe done in 0:01:04.814513: "document_class": undetected, "face": {'size': {'width': 640, 'height': 480}, 'bounds': [{'top': 306, 'right': 381, 'bottom': 476, 'left': 211}], 'vectors': '...'}, "extracted_text": "
Здесь указан тип документа, сэмплы результат обработки лиц и извлечения текста, время затраченное на обработку.
На стороне Staffcop лог /var/log/staffcop/process.log, начало и конец запуска обработки серии событий:
2020-09-10 12:19:38,877 [INFO] graphic_objects_detector:152 Графические объекты: process range 53793 - 53840
...
2020-09-10 12:26:14,148 [INFO] graphic_objects_detector:212 Графические объекты: finished at 53840. Time: 0:06